私のオンライン会議用音響機器遍歴
コロナ禍以降、オンラインでのミーティングが多くなりました。
「この人の音声、聞き取りづらいことが多いな」とか逆に「この人の音声はすごくクリアで聞き取りやすいな」と感じること、ありますよね?
この違いはどこから来るのだろうか?自分の声は相手に聞き取りやすく届いているのだろうか?
そんなふうに思ったこと、ありませんか?
もちろん機械に高いお金を掛ければいい音になるはずです。でも、世の中にはたくさんのマイクやらヘッドフォンやらスピーカーやらが存在しており、何を選べば快適にオンラインミーティングを行うことができるのでしょうか?
そう思っていろいろ試行錯誤した結果たどり着いた、今のところの答えは、ずばり
を利用することです。(もちろん今後私の経験や知識のアップデート、技術の革新などで最適解は変わる可能性があります)
この記事の残りは、その答えにたどり着いた理由とそこに至るまでの経緯をご説明します。
初期 - 内蔵スピーカー&内蔵マイク
いちばんはじめの頃は、特にこだわりもなかったので mac や PC に内蔵のスピーカーとマイクを利用していました。
たまに相手の声が聞き取りづらいとかこちらが言ったことが相手に聞こえづらかったといったようなことは起こっていましたが、そういうものだと思ってあまり気にしていませんでした。
しかしコロナ禍になり、オンラインミーティングの機会が急激に増加したことでだんだんとそういう小さなことであっても回数が増えるとストレスに感じるようになりました。
あとになって気づいたのですが、この内蔵スピーカー&内蔵マイクという構成には致命的な問題があります。
それは、スピーカーの音を常にマイクが拾っている状態である、ということです。これは物理的にしょうがないことなので通常はエコーキャンセラー機能が働くようになっていて問題は起こらないはずなのですが、PC の負荷が高い状態とかだと少し処理が遅れたりするからなのか、エコーキャンセラーがうまく働かず、一瞬だけ音声がループして聞こえる状態になることがあります。自分が話した内容が相手のマイクに拾われて自分に聞こえること、たまにありますよね?それは相手の PC でそのエコーキャンセルの失敗が起こっているということです。自分の環境でも起こっていないとは考えづらいので、他の人に迷惑をかけていることもあるかもしれないわけです。
これはスピーカーもマイクも PC 本体に内蔵されているという構造上、物理的に避けようがない欠点です。
他にも、細かいですがこの構成には以下のような問題があります:
- ❌ 通常は PC から少し離れたところで発話する(画面や PC 本体に数 cm 程度まで顔を近づけて話をする人はいませんよね?)と思うので、その音声を拾うためと思われますがマイクの感度が高く設定されているのか集音性能の良いマイクが使われているようで、周りの音(近くの席の人の声や物音)もたくさん拾ってしまいがちで、静かな部屋でないと雑音が多くなることがあります。
- キーボードを叩く音やマウスをカチカチする音、机にものを落とした音などが拾われたりして耳障りなことも多いです。
- ❌ ミーティング参加者の中の誰か一人でもこの内蔵スピーカー+内蔵マイクの(もしくは後述する同等の)構成の人がいて、その人が何か喋っている途中で他の人が不規則発言をすると、音声がごちゃっとなってかき消されてしまい(エコーキャンセラーの機能にも限界がある)、「今なんて言ったんですか?もう一回言ってもらっていいですか?」となりがち。(もしくはよくわからなかったけど聞き直すのも面倒なので聞こえたフリをしがち)
- ひとりずつ順番に発言すればよいだけ、と言われればそうなのですが、リアルに会って話をしているときとの一番大きな違い、スムーズなコミュニケーションの阻害要因がこの点だと思います。
この欠点はスピーカーフォン等も同じで、スピーカーから出る音(他人の声)と自分の声が同じ空間を利用する、言い換えると同じ空気を振動させる構成になっている以上は物理的に避けようがありません。
ということでこの致命的な欠点を避けるためには、マイクがスピーカーの音を物理的に拾わないようにしないといけないというのが絶対条件になります。
もちろん、通信環境の問題や PC のメモリ不足など他にも音声が乱れたり途切れたり聞き取りづらくなってしまう要因はあるのですが、それはそれとして別途解決するとして、そういった条件が理想的な状態になったとしても音響機器の問題で音声が聞き取りづらくなってしまうとしたらもったいないことです。
というわけで、ここから私的にベストな音響機器を探し求める試行錯誤が始まったのです。
マイク付きイヤフォン(有線)時代
スピーカーとマイクとが音が伝わる空間を共有してしまう問題を回避する方法として簡単なのが、有線接続でインナーイヤータイプのイヤフォン(マイク付き)を mac や PC に接続して使うことです。
こんなやつ↓
 イヤホン MDR-EX15AP : カナル型 リモコン・マイク付き ホワイト MDR-EX15AP W")
このタイプは何より比較的安価に入手できるのが良いところです。スマホに付属してきたものを使いまわしたりもできます。 マイクは PC 内蔵マイクに比べて口元近くにあり、周りの雑音を拾いにくいですし、イヤフォンとは物理的に少し離れているので(細い線でつながってはいますが)イヤフォンから発せられる音を(シャカシャカ音漏れするくらい大音量にでもしない限り)マイクが拾うこともなさそうなのでエコーキャンセラーの問題も心配が少なく、相手の声が聞きとりづらくなるようなことが減った感じがします。
今でも外出先とかではこのようなマイク付きイヤフォンでミーティングすることもあります。
しかし、この方式の最大の欠点は、長時間になると耳穴が痛くなるということです。
特に夏場はミーティング続きでイヤフォンをつけっぱなしだと耳の中が蒸れて痒くなったりしました。
また、マイクは口元に近いところにあるとはいえ、耳から垂れ下がっている状態なので、ちょっと体を動かしたりしたときに服と擦れてガサゴソと雑音が入ってしまうことがあります。
また有線タイプのイヤフォンは充電の必要がなく、ズボラな私にとっては便利なのですが、イヤフォンを使おうとしたときに線が絡まってしまっていて解くのに手間取ったり、席から立ち上がろうとしてイヤフォンをしていることを忘れていて線が引っかかってしまったりといった不便な点がありました。
有線ヘッドフォン+内蔵マイク時代
イヤフォンは耳穴を塞ぐ形になるので痛くなったり痒くなったりしてしまいますが、ヘッドフォンであればその問題は解消するかと思いイヤフォンをやめてヘッドフォンにしてみたこともあります。
言うまでもありませんが、こういうやつ↓

しかしヘッドフォンはすぐにダメだとわかりました。イヤーパッドで耳全体が覆われていますが耳全体が蒸れるようになっただけでした。しかも私は一般的な人より頭が大きい(頭囲64cm)ので、ヘッドバンドの締め付けもキツく、耳の周りや頭が痛くなりました。
また、耳全体が覆われるためか、自分の発した声がこもって聞こえる感じがして違和感があったのと、周囲の音が聞こえづらくなるので来客(玄関チャイム)に気づかないことがあるといった弊害もありました。
軽いタイプを試してみたり、耳全体を覆うのではなく耳の上にフィットする感じのヘッドフォン(↓のようなやつ)なども試してみましたが、耳や頭の痛さは解消されずダメでした。
![[国内正規品] ASHIDAVOX ST-90-07 ブラック オンイヤー アシダ音響 有線 ヘッドホン](https://m.media-amazon.com/images/I/41frqViWIDL._SL500_.jpg "[国内正規品] ASHIDAVOX ST-90-07 ブラック オンイヤー アシダ音響 有線 ヘッドホン")
有線タイプのヘッドフォンは有線イヤフォンと同じく配線の問題もありました。
それでも無線タイプは過去にちょっと充電の面倒さでトラウマがあってなるべく避けたいという思いがこのときはまだありました。
(充電ケーブルが USB ではなく特殊な形状の専用のものだったり、単に充電しわすれていていざというときに電池切れで使えなかったり、等)
また、この方式だとマイクは PC 内蔵のものを使うので、周囲の雑音を拾いやすいといった問題は一部残ります。
耳掛けヘッドセット時代
そこで次はヘッドセットを購入してみました。コールセンターのオペレーターさんや飛行機のパイロットが使ってそうな感じの、ヘッドフォンにマイクのアームがついているタイプのものです。
こんな感じの↓

だだしヘッドフォンはネックバンドタイプ(耳に引っ掛けるタイプ)でオープンイヤー型のものにしました。長時間装着していても耳や頭が痛くなりづらいだろうと期待してのことです。
実際に買ったのはコレ↓
 耳をふさがないヘッドセット「コールミーツ(有線タイプ)」")
結果として、ヘッドフォンやイヤフォンほどの不快さはありませんでしたが、やはり長時間つけていると耳にヘッドセットを引っ掛けている部分が少し痛むのと、意外な欠点としてマイクのアームに手が触れてしまうということがありました。
私はミーティング中にあれこれ考えると顔を触ってしまうというクセがあるということにこの時初めて気づきました。そしてそのクセで顔を触るときに手がマイクアームにあたってしまい、雑音が入ってしまうという問題に繋がりました。
また、ネックバンドが椅子のヘッドレストと干渉するという問題もありました。
ちなみにヘッドセットタイプはマイクの音質が比較的良いようで(口元にマイクがあるためと思われます)、ミーティング相手からも音声が聞き取りやすいと言われました。しかし、上記 2 点がどうしても気になってしまい、次の候補を探すことにしました。
USB ダイナミックマイク + オープンイヤータイプのイヤフォン(無線)時代
マイクを口元近くに配置する+音は空間に漏らさないという2つの条件を実現する構成として、いよいよ専用のマイクを使うことを考えました。ユーチューバーとかが使ってそうなやつです。

マイクを選ぶ上で、大きく分けてダイナミックマイクと呼ばれるタイプのマイクとコンデンサーマイクと呼ばれるタイプのマイクの 2 種類があることを知りました。
それぞれ長所・短所があるようですが、コンデンサーマイクは感度が良い反面、ノイズも拾いやすいとのことだったのでダイナミックマイクを使ってみることにしました。
値段はピンキリですが、高価なマイクの中には USB 接続ではなくXLR と呼ばれる端子で接続するものがあったりするので注意が必要です。それを PC に接続するには別の機器が必要となり、追加の費用がかかります。USB 接続可能なものを選びましょう。
また、マイクの指向性(カーディオイド)もいくつかのパターンがあります。ミーティング用で PC の前で自分一人がしゃべる音声を拾うことができればよいので、単一指向性のマイクが良いと思います。
今回は音響に詳しい同僚の勧めもあって、SHURE の MV7+ という機種にしました。妻には「ユーチューバーになるの?」と言われました。
これをフレキシブルアームタイプのマイクスタンド等を使って口元近くに配置します。
買ったのはコレ↓

机に置くタイプのマイクスタンドだと、キータイプ音とかを机経由で拾ってしまうとの情報があったので、マイクは浮かせて配置するのがよさそうということからフレキシブルアームを使うことにしました。
上から提げるような形で配置できるアームはかっこいいですが、Web カメラに写り込んでしまったり画面を見る際に邪魔になりそうだったので、下からマイクを支える形のアームにしました。
音を聞く方は今度は耳掛け式のオープンイヤータイプの無線 (Bluetooth 接続) イヤフォンにしてみました。
買ったのはコレ↓
 オープンイヤー イヤホン ワイヤレスイヤホン 超軽量 耳を塞がない 耳掛け式 究極のフィット感 イヤフォン 骨伝導の革新 DSP機能 オープンイヤーヘッドホン 業界トップ音質 指向性音伝送技術 音漏れ無し 日本語音声 Bluetooth5.3/マルチポイント接続/ENC通話ノイズリダクション (ブラック)")
耳掛け式のイヤフォンであれば、耳穴が痛くなるとか蒸れるといったこともありませんし、かなり軽いので重さによる問題もないか大幅に軽減されそうですし、ヘッドバンドやネックバンドに起因する問題も起こりません。そしてついに覚悟を決めて有線を諦め、無線タイプにしました。無線タイプのイヤフォンは最近は専用のケースにしまっておくと充電されるものが多いようで、充電し忘れは防げそうでしたので私の懸念はある程度払拭されました。無線にして最大のメリットは、線に起因するいくつかの問題が起こらないということです。数メートル程度であれば机から離れても接続が途切れることもなく、ミーティング中に少し動き回れるというのは思った以上にメリットでした。
結果としてこの構成は自分としてはだいぶ快適だったのですが、オープンイヤータイプのイヤフォンは耳元に小さなスピーカーを置いているようなものなので、若干の音漏れがあります。そしてマイクが口元近くにあり、すなわち耳元にも比較的近い所にあるということなので、その音漏れをマイクが拾ってしまうようで、「空間を共有しない」という原則に反してしまっているということに気づきました(マイクのインジケーターがその音漏れに反応して光っていたので気づくことができました)。
これではエコーキャンセラーがその仕事を失敗したときに音声がエコーしてしまうことになり、ミーティング参加者の音響体験を下げることになってしまいます。
そんなわけでその問題を解決する答えをまた探すことになりました。
USB ダイナミックマイク + 骨伝導タイプのイヤフォン(無線)時代 - 現在
空気を共有しないためにはもう骨伝導タイプにするしかないだろう(骨伝導であれば空気を振動させるわけではないので)、という結論に達し、いろいろ探してみたのですが、有名な Shokz の骨伝導イヤフォンはすべてネックバンドタイプでした。ネックバンドはヘッドセットのときに懲りたので、できれば片耳づつ掛けられるセパレートタイプかつ骨伝導タイプのイヤフォンが良いなと思って探しましたが、これがなかなか見つかりません。
骨伝導タイプはオープンイヤータイプなどのように耳掛けにするのが技術的に難しいのかもしれません。肌に密着させなければ音が伝わらないからなのか、はたまた消費電力などの問題なのか、理由はわかりませんが、とにかく検索しても全く出てきません。
実際には検索すると Aliexpress などでわんさか出てくるのですが、それらは実際には骨伝導ではなくてただのオープンイヤータイプのイヤフォンなのです。堂々と骨伝導とか Bone conduction とか書いているのに届いてみたら普通のオープンイヤータイプでガンガン音漏れするやつを騙されて1つ買ってしまいました・・・
何ヶ月か時々思い出しては検索してみて、やっと見つけたのが以下の製品です。

これも届いてみるまでは本当に骨伝導かどうか不安がありましたが、届いた製品を見る限り、確かに空気で音を伝えるための穴のようなものは見当たりませんでしたので骨伝導っぽい感じがします。実際に音を鳴らしてみると、耳のあたりの皮膚にピッタリとくっついていなくても、耳の近くにあるだけで音は聞こえてしまいます。つまり音漏れはします。本体が振動することで空気も振動してしまうのだと思います。しかしながら実際に装着しながら音を鳴らしてみてもマイクのインジケーターを見ると音漏れを拾っている感じはしないので問題は解消されている気がします。
まとめ
というわけで、現在 2025 年末時点での私的にベストな組み合わせにようやくたどり着いた感じがしています。ですが、冒頭にも書いたように今後私の経験や知識がアップデートされたり技術革新が起こったりしたらベストな答えが変わっていくかもしれません。
できればオンラインミーティングに参加する人全員が可能な限り「マイクとスピーカーが空気を共有しない方式」でミーティングに参加して欲しいと思います。なぜなら、一人でも「空気共有方式」の参加者がいると、それだけで音声が壊滅することがあり、ミーティングの効率を下げてしまうからです。 イヤフォンやヘッドフォンを装着しても頭や耳に問題が生じない方はそれでも良いでしょうし、ヘッドセットでマイクアームに手があたってしまうという問題が起こらない人はそれで良いと思います。みなさんそれぞれベストな方式を見つけてほしいと思います。 もしくは、「こんな方法もあるよ」といった情報があればぜひ教えてください。
この記事がみなさんのオンラインミーティングの音響体験を少しでも改善する一助になればと願っています。
Wayland でお好みのキーバインド
だいぶ前に以下のような記事を書きました。
しかし時は下って Ubuntu 22.04 では Wayland がデフォルトのコンポジターになっており(実際には 21.04 からデフォルトになったみたいです)、そのため X.org では使えていた xmodmap が使えなくなってしまいました。Wayland を使うのをやめて X.org に戻すこともできたので、以前 Ubuntu 22.04 をインストールしたときは急いでいたということもあってその方法を取りました。
しかし今回再び Ubuntu 22.04 をインストールしてセットアップすることになったので、今度こそは Wayland で使える xmodmap と同等の方法を見つけ出そうと思っていろいろ調べました。
いろいろな情報が見つかりましたが、xmodmap そのものを単純になにか単一の別のもので置き換えることはできず、複数の方法を組み合わせる必要がありそうということはわかりました。
私が最終的に落ち着いたのは、
- udev で単純なキーボードのリマップ(CapsLock を Ctrl に置き換えるなど)を行い、
- xremap でキーバインド(モディファイヤキー+何らかのキーの組み合わせで別のキーが押されたことにしたり何らかのコマンドを発行したりする)の設定をする
という方法です。
💡
このような設定を行いたい場合、xremap の設定ファイルには以下のように記述するかと思います。
CapsLock -> LeftCtrl から LeftCtrl -> LeftMeta に連鎖してしまっているような感じの動きに見えました。
同じように LeftCtrl -> LeftMeta から LeftMeta -> LeftAlt に、LeftMeta -> LeftAlt も LeftAlt -> Fn に連鎖してしまっているような感じでした。
記述の順番等を変えてみたりもしましたが同様でした。
xremap の問題かもしれませんし私の記述の仕方の問題かもしれませんが、ちょっと解決策がわからなかったので今回はリマップは xremap 以外の方法で行うこととしました。
xremap 単体でもキーボードのリマップはできるのですが、私が行いたかった以下のような変更を実施すると思ったような結果とならなかったためリマップは udev で行うこととしました。
私が行いたかった変更とは、
- 左 Alt を何らかのモディファイヤキーに(例えば後述する virtual_modifiers を使って Fn キーをモディファイヤキーに)
- 左 Meta(Windows キー)を左 Alt に
- 左 Ctrl を左 Meta に
- CapsLock を左 Ctrl に
このような設定を行いたい場合、xremap の設定ファイルには以下のように記述するかと思います。
modmap:
- remap
LeftAlt: Fn
LeftMeta: LeftAlt
LeftCtrl: LeftMeta
CapsLock: LeftCtrl
しかしこの設定だと CapsLock を押したときに Ctrl ではなく Meta(Windows キー)を押したことになってしまいました。CapsLock -> LeftCtrl から LeftCtrl -> LeftMeta に連鎖してしまっているような感じの動きに見えました。
同じように LeftCtrl -> LeftMeta から LeftMeta -> LeftAlt に、LeftMeta -> LeftAlt も LeftAlt -> Fn に連鎖してしまっているような感じでした。
記述の順番等を変えてみたりもしましたが同様でした。
xremap の問題かもしれませんし私の記述の仕方の問題かもしれませんが、ちょっと解決策がわからなかったので今回はリマップは xremap 以外の方法で行うこととしました。
というわけで、以下では
- udev を使ったキーリマップの設定
- xremap を使ったキーバインディングの設定
を順に説明していきます。
1. udev を使ったキーリマップの設定
いろいろなページを見ましたが、キーのリマップをするのには udev を使っているものがほとんどでした。
その中でも、udev を使ってキーのリマップをすることに関する記述で一番正確だと感じたのは以下のページでした。
このページに書かれている内容を要約すると以下の 4 つのステップになります。
- キーを押したときに発生する「スキャンコード」を調べる
/etc/udev/hwdb.d/にスキャンコード → キーコード(どのキーが押されたことにするか)の対応関係を書くsudo systemd-hwdb updateを実行して hwdb を更新sudo udevadm triggerを実行して hwdb の変更を適用
以下、私が具体的に行った作業を例に、順に解説していきます。
1-1. キーを押したときに発生するスキャンコードを調べる
まず、どのキーが押されたらどのようなスキャンコードが発生するかを調べます。それには evtest というコマンドを使います。
evtest コマンドを、特に引数は指定せずにルートユーザー権限で実行します。
$ sudo evtest No device specified, trying to scan all of /dev/input/event* Available devices: /dev/input/event0: Sleep Button /dev/input/event1: Power Button /dev/input/event2: Lid Switch /dev/input/event3: AT Translated Set 2 keyboard /dev/input/event4: Topre REALFORCE 87 US /dev/input/event5: Topre REALFORCE 87 US Consumer Control /dev/input/event6: Topre REALFORCE 87 US Keyboard /dev/input/event7: Intel HID events /dev/input/event8: Intel HID 5 button array /dev/input/event9: Apple Inc. Magic Trackpad 2 /dev/input/event10: Wacom One by Wacom M Pen /dev/input/event11: Apple Inc. Magic Trackpad 2 /dev/input/event12: Video Bus /dev/input/event13: HDA Intel PCH Mic /dev/input/event14: HDA Intel PCH Headphone /dev/input/event15: HDA Intel PCH HDMI/DP,pcm=3 /dev/input/event16: HDA Intel PCH HDMI/DP,pcm=7 /dev/input/event17: HDA Intel PCH HDMI/DP,pcm=8 /dev/input/event18: HDA Intel PCH HDMI/DP,pcm=9 Select the device event number [0-18]:
このような形でシステムに接続されている入力デバイスがずらずらと列挙されると思います。
そして最後に番号を選ぶように言われているので、自分のキーボードの名前が表示されている行の /dev/input/event* の番号の部分を入力します。
すると、以下のようにキーコードの一覧がずらーっと表示されると思います。
Input driver version is 1.0.1
Input device ID: bus 0x3 vendor 0x853 product 0x145 version 0x111
Input device name: "Topre REALFORCE 87 US"
Supported events:
Event type 0 (EV_SYN)
Event type 1 (EV_KEY)
Event code 1 (KEY_ESC)
Event code 2 (KEY_1)
Event code 3 (KEY_2)
Event code 4 (KEY_3)
Event code 5 (KEY_4)
Event code 6 (KEY_5)
Event code 7 (KEY_6)
Event code 8 (KEY_7)
Event code 9 (KEY_8)
Event code 10 (KEY_9)
Event code 11 (KEY_0)
Event code 12 (KEY_MINUS)
Event code 13 (KEY_EQUAL)
Event code 14 (KEY_BACKSPACE)
Event code 15 (KEY_TAB)
Event code 16 (KEY_Q)
Event code 17 (KEY_W)
Event code 18 (KEY_E)
Event code 19 (KEY_R)
Event code 20 (KEY_T)
Event code 21 (KEY_Y)
Event code 22 (KEY_U)
Event code 23 (KEY_I)
Event code 24 (KEY_O)
Event code 25 (KEY_P)
...
そして最後に以下のような表示で止まると思います。
...
Key repeat handling:
Repeat type 20 (EV_REP)
Repeat code 0 (REP_DELAY)
Value 250
Repeat code 1 (REP_PERIOD)
Value 33
Properties:
Testing ... (interrupt to exit)
Event: time 1701488985.557366, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70028
Event: time 1701488985.557366, type 1 (EV_KEY), code 28 (KEY_ENTER), value 0
Event: time 1701488985.557366, -------------- SYN_REPORT ------------
ここで、置き換えたいキーをいろいろ押してみましょう。すると、以下のように表示が増えていくと思います。
Event: time 1701488990.899371, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70039 Event: time 1701488990.899371, type 1 (EV_KEY), code 58 (KEY_CAPSLOCK), value 1 Event: time 1701488990.899371, -------------- SYN_REPORT ------------ Event: time 1701488990.899543, type 17 (EV_LED), code 1 (LED_CAPSL), value 1 Event: time 1701488990.899543, -------------- SYN_REPORT ------------ Event: time 1701488991.057316, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70039 Event: time 1701488991.057316, type 1 (EV_KEY), code 58 (KEY_CAPSLOCK), value 0 Event: time 1701488991.057316, -------------- SYN_REPORT ------------ Event: time 1701488993.972222, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e0 Event: time 1701488993.972222, type 1 (EV_KEY), code 29 (KEY_LEFTCTRL), value 1 Event: time 1701488993.972222, -------------- SYN_REPORT ------------ Event: time 1701488994.114176, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e0 Event: time 1701488994.114176, type 1 (EV_KEY), code 29 (KEY_LEFTCTRL), value 0 Event: time 1701488994.114176, -------------- SYN_REPORT ------------ Event: time 1701488994.671199, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e3 Event: time 1701488994.671199, type 1 (EV_KEY), code 125 (KEY_LEFTMETA), value 1 Event: time 1701488994.671199, -------------- SYN_REPORT ------------ Event: time 1701488994.813167, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e3 Event: time 1701488994.813167, type 1 (EV_KEY), code 125 (KEY_LEFTMETA), value 0 Event: time 1701488994.813167, -------------- SYN_REPORT ------------ Event: time 1701488995.433148, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e2 Event: time 1701488995.433148, type 1 (EV_KEY), code 56 (KEY_LEFTALT), value 1 Event: time 1701488995.433148, -------------- SYN_REPORT ------------ Event: time 1701488995.559108, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e2 Event: time 1701488995.559108, type 1 (EV_KEY), code 56 (KEY_LEFTALT), value 0 Event: time 1701488995.559108, -------------- SYN_REPORT ------------
(MSC_SCAN) の右隣の value の 16 進数が今回取得したい「スキャンコード」です。たとえば CapsLock を押したときは
Event: time 1701488990.899371, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70039 Event: time 1701488990.899371, type 1 (EV_KEY), code 58 (KEY_CAPSLOCK), value 1
このような 2 行が表示されると思います。
1行目は物理的なキーを押したときに発生したスキャンコードで、私のキーボードでは CapsLock のスキャンコードは 70039 であることがわかります。
USB 接続のキーボードだと 70039 のような 5 桁の値になるようですが、PS/2 接続のキーボードだと 3e のような 2 桁の値になるようです。
2行目はそのスキャンコードがどのようなキーコードとして解釈されたかを表しています。KEY_CAPSLOCK と書かれているので CapsLock キーとして解釈されたことがわかります。
置き換えたいキーをすべて押して、それらのスキャンコードがわかったら、Ctrl-C を押して終了します。
1-2. /etc/udev/hwdb.d/ にスキャンコード → キーコード(どのキーが押されたことにするか)の対応関係を書く
私の場合は以下のような置き換えをしたいと考えています。
- 左 Alt を何らかのモディファイヤキー(たとえば Fn)に
- 左 Meta(Windows キー)を左 Alt に
- 左 Ctrl を左 Meta に
- CapsLock を左 Ctrl に
ですので、先ほど evtest コマンドを使って 左 Alt (KEY_LEFTALT)、左 Meta (KEY_LEFTMETA)、左 Ctrl (KEY_LEFTCTRL)、CapsLock (KEY_CAPSLOCK) を押してスキャンコードを取得しました。
これらのスキャンコードが希望するキーコードに解釈されるような変換ルールを /etc/udev/hwdb.d/ 以下のファイルに書いていきます。
拡張子が .hwdb であればファイル名は何でも良いようですが、ファイル名の順番にルールが適用されるようですので、慣習的には 10-mykeyboard.hwdb のように 2 桁の数字で始まる名前にするようです。
私の場合は以下のような内容でファイルを作成しました。
evdev:input:b0003v0853p0145e* KEYBOARD_KEY_700e2=fn KEYBOARD_KEY_700e3=leftalt KEYBOARD_KEY_700e0=leftmeta KEYBOARD_KEY_70039=leftctrl
1 行目は、この変換ルールを適用する対象となるデバイスを絞り込むためのものです。
USB 接続のキーボードの場合は
evdev:input:b<bus_id>v<vendor_id>p<product_id>e<version_id>-<modalias>
というフォーマットで指定します。
AT キーボード(おそらく PS/2 接続のキーボードのこと?)の場合は
evdev:atkbd:dmi:bvn*:bvr*:bd*:svn<vendor>:pn<product>:pvr*
というフォーマットになるようです。
もう一つ、以下のような指定の方法もあるようです。
evdev:name:<input device name>:dmi:bvn*:bvr*:bd*:svn<vendor>:pn*
どのような場合に使うのかは私にはわかりませんが、USB 接続でも PS/2 接続でもないキーボード(例えば仮想キーボード?)の場合に使用するのかもしれません。
私は USB 接続タイプの RealForce を使っていますが、その場合は一番めのフォーマットで USB のバス ID (0003 固定)、ベンダー ID、プロダクト IDを指定します。バージョン番号とかも指定することができるようにはなっていますが、さすがにそこまで細かい指定はが必要になるのは稀かと思うのでワイルドカードにすることもできます。
ベンダー ID とプロダクト ID は先ほど evtest コマンドを実行してキーボードの番号を選んだ直後くらいに表示されていますのでそれを用います。バス ID、ベンダー ID、プロダクト ID いずれも 16 進数ですが先頭の 0x は不要で数値部分だけ指定します。
このデバイスを指定する行に続けて、 半角スペース 1 つのインデント 1 で KEYBOARD_KEY_<scancode>=<keycode> という感じの行を書いてスキャンコード→キーコードの対応を書いていきます。
スキャンコードは先ほど evtest コマンドを使って収集した 16 進数の値です。
キーコードは Linux のヘッダー input-event-codes.h に定義されている KEY_<keycode> という感じの文字列の <keycode> 部分を 小文字 にしたものです。
(Linux のヘッダー input-event-codes.h が見当たらない場合は、後述する xremap の README からリンクされていますが、xremap のソース を参照しても良いと思います)
私の場合の例の以下の行
KEYBOARD_KEY_700e2=fn
は、スキャンコード 700e2(物理的な左 Alt キー)が押されたときに KEY_FN というキーコードとして解釈する、という設定です。
同様に
KEYBOARD_KEY_700e3=leftalt KEYBOARD_KEY_700e0=leftmeta KEYBOARD_KEY_70039=leftctrl
は、スキャンコード 700e3(物理的な左 Meta キー)を KEY_LEFTALT として、 700e0(物理的な左 Ctrl キー)を KEY_LEFTMETA として、 70039(物理的な CapsLock キー)を KEY_LEFTCTRL として解釈することを表しています。
1-3. sudo systemd-hwdb update を実行して hwdb を更新
変換ルールを書いたファイルができたら、それをコンパイルしてバイナリファイルにする必要があります。
これはコマンドを一つ実行するだけでできます。
$ sudo systemd-hwdb update
1-4. sudo udevadm trigger を実行して hwdb の変更を適用
hwdb のバイナリファイルができたら、それを適用します。
以下のコマンドを実行します。
$ sudo udevadm trigger
ここまで来ると、キーのリマップが完了した状態になっているはずです。
再度 evtest コマンドを実行してみて、今置き換えたキーを押してみましょう。
$ sudo evtest ... Event: time 1701491035.067116, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70039 Event: time 1701491035.067116, type 1 (EV_KEY), code 29 (KEY_LEFTCTRL), value 1 Event: time 1701491035.067116, -------------- SYN_REPORT ------------ Event: time 1701491035.241117, type 4 (EV_MSC), code 4 (MSC_SCAN), value 70039 Event: time 1701491035.241117, type 1 (EV_KEY), code 29 (KEY_LEFTCTRL), value 0 Event: time 1701491035.241117, -------------- SYN_REPORT ------------ Event: time 1701491038.436174, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e0 Event: time 1701491038.436174, type 1 (EV_KEY), code 125 (KEY_LEFTMETA), value 1 Event: time 1701491038.436174, -------------- SYN_REPORT ------------ Event: time 1701491038.610201, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e0 Event: time 1701491038.610201, type 1 (EV_KEY), code 125 (KEY_LEFTMETA), value 0 Event: time 1701491038.610201, -------------- SYN_REPORT ------------ Event: time 1701491038.898182, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e3 Event: time 1701491038.898182, type 1 (EV_KEY), code 56 (KEY_LEFTALT), value 1 Event: time 1701491038.898182, -------------- SYN_REPORT ------------ Event: time 1701491039.072185, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e3 Event: time 1701491039.072185, type 1 (EV_KEY), code 56 (KEY_LEFTALT), value 0 Event: time 1701491039.072185, -------------- SYN_REPORT ------------ Event: time 1701491039.754193, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e2 Event: time 1701491039.754193, type 1 (EV_KEY), code 464 (KEY_FN), value 1 Event: time 1701491039.754193, -------------- SYN_REPORT ------------ Event: time 1701491039.864188, type 4 (EV_MSC), code 4 (MSC_SCAN), value 700e2 Event: time 1701491039.864188, type 1 (EV_KEY), code 464 (KEY_FN), value 0 Event: time 1701491039.864188, -------------- SYN_REPORT ------------
スキャンコード 70039(物理的な CapsLock キー)が左 Ctrl キー(KEY_LEFTCTRL)として解釈されているのがわかると思います。 同様に 700e0(物理的な左 Ctrl キー)が左 Meta (KEY_LEFTMETA) に、700e3(物理的な左 Meta キー)が左 Alt (KEY_LEFTALT) に、700e2(物理的な左 Alt キー)が Fn キー(KEY_FN)として認識されています。
2. xremap を使ったキーバインディングの設定
続いて、キーバインディングを設定していきます。 キーバインディングとは、たとえば Fn+H / J / K / L で←↓↑→ の方向キーと認識されるようにするための設定です。
これを行う方法はいくつかありそうでしたが、 xremap を使うのが令和最新版のような感じがしました。
xremap の README を読めばインストール方法や設定方法はだいたいわかると思いますが、念のためこちらもまとめて行きます。
大まかには以下のような順番で作業を行っていきます。
- Rust をインストール(もしインストールされていなければ)
- cargo で xremap をインストール
- sudo なしで xremap を実行できるように設定
- xremap の設定ファイルを作成
- テスト実行
- ログイン時にバックグラウンドで自動実行されるようにする
2.1 Rust をインストール(もしインストールされていなければ)
xremap は cargo を使ってインストールする方法を取ります。cargo を利用するのに特に深い理由はありません。 そこそこ安定してそうなのでコンパイル済みのバイナリを使ってインストールしても良さそうではあります。
xremap の README にも書いてあるように、Rust とそのパッケージマネージャーである cargo をインストールするには rustup を使います。
今どきのプログラマであれば Rust くらいすでにインストール済みかもしれませんが、新しく構築するまっさらな環境で xremap を使いたいような場合は Rust のインストールが必要なので一応書いておいたという感じです。特に難しいことはないと思うのでここでは詳細には触れません。
2.2 cargo で xremap をインストール
これも特に難しいことはないかと思います。
xremap の README に書いてあるように、cargo install xremap を実行します。今回は Wayland で動かすので
cargo install xremap --features gnome # GNOME Wayland
こちらの feature を選択します。
2.3. sudo なしで xremap を実行できるように設定
これも xremap の README に書いてありますが、以下の 2 行を実行します。
sudo gpasswd -a "$USER" input echo 'KERNEL=="uinput", GROUP="input", TAG+="uaccess"' | sudo tee /etc/udev/rules.d/input.rules
これにより、自分のユーザーが input というグループに入り、input グループには uinput へのアクセスが許可されるようなルールが追加されます。
2.4. xremap の設定ファイルを作成
xremap のREADME を読めばどのような設定ファイルを作ればよいかがわかると思います。
私の場合は以下のような内容の設定ファイルを作りました。
virtual_modifiers:
- fn
keymap:
- remap:
fn-a: home
fn-e: end
fn-d: delete
fn-h: left
fn-j: down
fn-k: up
fn-l: right
ファイルを保存する場所やファイル名は何でも良いようです。
私は xremap_conf.yaml というファイル名にして、dotfiles ばかりを集めて Git で管理しているディレクトリに入れました。
私の書いた設定の内容を解説しますと、まず virtual_modifiers: ですが、これは本来モディファイヤキー(Ctrl や Shift のような修飾キー)でないキーをモディファイヤキーのように扱えるようにする xremap の機能です。
何でも良かったのですが私は Fn キーを選びました。(ちなみに RealForce には物理的に Fn キーがありますが、これを押してもスキャンコードは発生しません。他のキーと組み合わせて押したときに一部のキーで発生するスキャンコード自体が変わるようです)
次の keymap: にはシンプルなキーバインドをいくつか設定しています。
keymap の子要素の名前が remap なのでちょっと分かりづらいですが、単純なリマップ(キーの置き換え)だけでなくキーバインドを定義することができます。
私の場合は Fn キーとの組み合わせで Fn + a で Home キー、Fn + e で End キー、Fn + d で Delete キー、Fn + h / j / k / l で ←↓↑→ となるような設定を書きました。
なお、この remap に指定する各要素はいろいろな書き方ができて、単純なキーバインドだけでなく、キーバインドからキーのシーケンスを生成するようなこともできますし、何らかのコマンドを実行したりもできますし、他にもいろいろなことができそうです。
私が使ったのは以下の一番シンプルな形式の設定です。
MOD1-KEY_XXX: MOD2-KEY_YYY
MOD1- や MOD2- の部分は、SHIFT- CTRL- ALT- SUPER- のいずれか(およびそれらのバリアント)を指定できます。私の場合は Fn を virtual modifier として使っています。モディファイヤキーの指定は省略することもできます。
KEY_XXX や KEY_YYY の部分はキーコードです。KEY_ を省略して XXX や YYY だけ書くこともできます。
また、モディファイヤキー部分もキーコード部分もすべて大文字小文字どちらでも指定することができます。
つまり KEY_CAPSLOCK も CAPSLOCK も CapsLock も capslock もすべて同じ意味です。
私はすべて小文字で書きました。
2.5. テスト実行
設定ファイルができたら、思うように動作するか確認してみましょう。 以下のように xremap コマンドを実行します。
$ xremap ${conf_file}
${conf_file} は設定ファイルのパスに置き換えてください。
このコマンドを実行すると、設定ファイルにエラーがなければ xremap が入力デバイスの一覧を表示し、どのデバイスからの入力に対して適用するかを自動的に判別していることなどが表示されます。
この状態ですでにキーバインドが使えるようになっているので試してみましょう。
どうでしょう?うまく動いていましたか?
動作を確認したら Ctrl-C で終了します。
2.6. ログイン時にバックグラウンドで自動実行されるようにする
思ったとおりの設定ができたことが確認できたら xremap がログイン時に自動実行されるようにしましょう。 (以前、似たような話題で記事を書いたことがあります: Ubuntu 20.04 で GUI 起動時に任意のプログラムを実行したい - bearmini's blog )
しかしそこに書いた方法だと、キーボードを抜いたときに xremap がキーボードの存在を見失ってしまって、キーボードを挿し直しても上で行った設定が反映されないということがわかりました。
再度設定を反映させるには xremap コマンドを終了して再実行する必要があります。
キーボードを挿し直すようなことはめったにしないのでそれでも別に良かったのですが、最近新しく購入したディスプレイが KVM の機能を持っていて、ディスプレイの入力を他の PC 等に切り替えたタイミングでキーボードが抜かれたのと同じ状態になってしまって元の PC に戻ってきても設定が反映されていないという事象が起こるようになりました。入力切り替えだけでなく、ディスプレイがスリープに入るタイミングでも同じようなことが起こっているようで、非常に不便になってしまいました。
そこでそれを解決する方法として xremap を systemd で実行するようにしておき、udev rule をもう一つ作成して、キーボードが接続されたタイミングで systemctl restart コマンドを実行して xremap を再実行するようにします。
USB 接続のキーボードの場合は lsusb コマンドを実行して Vendor ID と Product ID を特定しておきます。
$ lsusb Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub ... Bus 003 Device 040: ID 0853:0145 Topre Corporation REALFORCE 87 US ...
私の場合は Topre の RealForce を使っているので該当する行がわかりました。読者の皆様のキーボードも同じようにメーカー名や製品名、モデル名が表示されると思いますのでその情報を頼りに該当する行を特定してください。
その行の ID のあとの 4 桁の 16 進数が Vendor ID で、: のあとの 4 桁の 16 進数が Product ID です。
これらの値は後で使うのでメモしておきます。
次に、xremap を systemd 管理下で実行するために、 /etc/systemd/system/ ディレクトリの中に xremap.service のような名前で以下のような内容のファイルを作成します。
[Unit] Description=Start xremap [Service] Type=simple ExecStart=/home/<username>/.cargo/bin/xremap /home/<username>/dotfiles/xremap_conf.yaml Restart=always [Install] WantedBy=multi-user.target
ExecStart の行の xremap コマンドのパスと、設定ファイルのパスは適宜ご自身の環境に合わせて書き換えてください。
以下のコマンドを実行し、systemd にこの新しい設定ファイルを有効化し実行します。
sudo systemctl enable xremap.service sudo systemctl start xremap.service
この時点で xremap に設定したキーバインドが使えるようになっているはずです。
しかしここでいったんキーボードを抜いて挿し直してみてください。キーバインドが使えなくなってしまっているはずです。systemctl status xremap コマンドなどでログを見ると、xremap がキーボードを見失ったようなログが見られますが、挿し直しても自動で再認識された様子はないと思います。
挿し直したときに自動的に xremap を再実行できるように、udev の rule を追加しましょう。
/etc/udev/rules.d/ ディレクトリの中に 99-restart-xremap-on-keyboard-connected.rules のような名前で以下のような内容のファイルを作成します。
SUBSYSTEM=="input", ACTION=="add", ATTRS{idVendor}=="0853", ATTRS{idProduct}=="0145" RUN+="/usr/bin/systemctl restart xremap.service"
ATTRS{idVendor}== のあとの 4 桁と ATTRS{idProduct}== のあとの 4 桁は先ほど lsusb コマンドを実行して確認した値に置き換えてください。
ファイルを作成したら以下のコマンドを実行して今追加した rule を有効化します。
sudo udevadm control --reload sudo udevadm trigger
この状態でキーボードを抜き挿ししてみましょう。
挿し直したあとにもキーバインドが有効になっているはずです。 また、PC を再起動したりログインしなおしたりしても同様にキーバインドが使えるようになっていると思います。
date コマンドが辛かったので、自分的最強日付時刻取り扱いコマンドを作りました。
以前、以下のようなぼやきを書きました。
もう 5 年以上前になるんですね。
その後も、ときどき date コマンドの辛さを味わっては何とかしたいと思い続けて来ました。
一方、今年の夏、私は fq というコマンドに出会いました。
この fq 自体は、date コマンドとは何の関係もありません。jq のようなフィルタ構文を使ってバイナリファイルの解析ができるという超便利なツールです。
<自慢>
ちなみに私はこの
fqで WASM のバイナリが解析できるようにするためのプルリクエストを送ってマージされました。😤</自慢>
jq の構文を JSON の操作以外のことに使ってもいいんだということに fq のおかげで気付くことができて、しかもそれがかなり強力なものであるということがわかりました。
ちなみに
fqの作者の wader さんは、jq で jq を実装するという意味のわからないことをしている人でもありますw
で、この fq が jq っぽいことができているのは gojq というパッケージのおかげだということを知りました。
gojq はライブラリとして Go のプログラムに比較的かんたんに組み込むことができそうでした。
ここまで来たときに、「もしかして、日付や時刻を表すさまざまな表現を jq のような構文でゴニョゴニョできたらめっちゃ便利だったりしないかな?」という妄想が私の脳の片隅に浮かびました。
たとえばこんな感じです。
$ echo 1669872594 | dq 'from_unix | add(72 | hours) | to_rfc3339' "2022-12-04T14:29:54+09:00"
すなわち、数値や文字列など何らかの形式で日付時刻を表すデータが標準入力から与えられた時に、それを元に「日付時刻オブジェクト」のようなものを内部的に生成し(上の例では Unix 時刻 1669872594 を与えているので from_unix で Unix 時刻から「日付時刻オブジェクト」を生成している)、必要に応じて計算を行って(上の例では add(72 | hours) で 72 時間後の時刻を計算)、それを任意の形式で出力(上の例では RFC 3339 の形式の文字列に変換)する、というようなことが慣れ親しんだ jq の構文でできるようになりそうです。
そんなわけで、開発したのがこちらです:
dq コマンドをインストールすると、上の例がそのまま実行できます。
詳しい使い方は README を見ていただければと思いますが、我ながらとてつもなく便利なものを作ってしまったなと思っています。
たとえば、date コマンドつらい に書いた以下のようなこともクロスプラットフォームで同じ書き方ができるようになっています。
単に
dateコマンドを実行したときと同じ出力を得たい$ dq -r tounixdate Thu Dec 1 22:24:24 JST 2022-rオプションはjqと同じで raw output すなわち文字列の周りのダブルクオーテーション"〜"を省略します。tounixdateという関数の名前はtounixdateという具合に分解されて、つまりdateコマンドの標準のフォーマットに変換するものです。このコマンドには標準入力に何も与えていないので、デフォルト動作として現在時刻(コマンドを実行した瞬間の時刻)を表す time オブジェクトに対して関数が適用されます。
現在の日時を指定のフォーマット(ここでは
%Y-%m-%d)で出力したい$ dq -r '.unix | strftime("%Y-%m-%d")' 2022-12-01strftime関数は実はjqに元から備わっている関数で、gojqを使っていると自動的に使えるようになっている関数の一つです。内部的には C 言語のライブラリ関数のstrftime()を呼び出しているようです。なのでstrftime()関数と同じフォーマット指定子を使うことができます。strftime()関数には Unix time を入力する必要があるので、.unixで現在時刻の Unix time を取得して与えています。昨日の日付を出力したい
$ dq -r 'add_date(0;0;-1) | tounixdate' Wed Nov 30 22:27:38 JST 2022日時の加減は
add_date関数、もしくはadd関数を使います。(減算もadd_dateやaddに負の値を与えて行います) 年月日を加減算したい場合はadd_dateを使うのが便利です。 時分秒を加減算したい場合はaddを使うのが便利です。add_date関数には 3 つの引数で「年」「月」「日」のそれぞれの差分を指定します。jqの関数は引数の区切りがカンマではなくセミコロンです。(カンマは JSON の中などで使うので紛らわしいのでセミコロンになっているのかな?) つまりadd_date(0;0;-1)は、年は変更なし、月も変更なし、日は-1すなわち 1 日前を表します。add関数にはduration(期間)オブジェクトを渡す必要があります。durationオブジェクトはhoursminutessecondsmillisecondsmicrosecondsnanosecondsのいずれかの関数(いずれも整数を入力してdurationを出力する関数)を使って、3 | hoursのように生成します。
最低限自分が必要とした基本的な機能は実装してあるつもりですが、まだまだ機能的には足りていないと思うので今後も継続的に育てていこうと思います。
皆様からのフィードバックもお待ちしております!GitHub の Issue や Pull Request はもちろん歓迎ですし、bitbears-dev 名義は英語で活動しておりますが「日本語じゃないと無理ー」という方は Twitter で @bearmini 宛にメンションしていただければと!
ソラカメ API を使いこなしてタイムラプス映像を作成する
みなさんこんにちは!
早いものでもう 12 月、今年もアドベントカレンダーの季節がやってきましたね。
この記事は SORACOM Advent Calendar 2022 の初日の記事です。
目次
ソラカメとソラカメ API
みなさん ソラカメ はご存知ですか?
ソラカメはソラコムが提供を開始した "クラウドカメラサービス" です。詳しいことはリンク先をご覧いただきたいのですが、クラウドに映像を常時録画しておいて後からその映像を確認できるなどの特徴があります。しかしなんと言ってもそのクラウドに記録された映像を API でダウンロードできたりするという点が私たちプログラマーにとっては最大の特徴と言えるでしょう。
今日は、その ソラカメ API の活用例をご紹介したいと思います!
細かい説明はすっ飛ばしてとにかく手っ取り早くタイムラプス映像を作成する方法を知りたい方は ソラカメ API を使ってタイムラプス映像を作るためのスクリプト まで一気に飛んでください。
ソラカメ API でできること
2022 年 12 月 1 日現在では、ソラカメ API を使って以下のようなことができます。
- カメラ一覧の取得
- カメラ詳細情報の取得
- リアルタイム映像の閲覧(ストリーミング形式)
- 常時録画の閲覧(ストリーミング形式)
- 常時録画データのエクスポート
- 常時録画データから切り出した静止画像のエクスポート
- 常時録画データもしくは静止画像のエクスポートの進捗状況の取得
API は今後も随時拡充される予定ですのでぜひお楽しみになさっていてください!
ソラカメ API の使い方
「ソラカメ API」と言っても、実はこれまでソラコムが提供してきた SORACOM API の一部です。
つまり、https://api.soracom.io などのエンドポイント経由で呼び出すことができますし、soracom-cli を使って呼び出すことももちろんできます。
soracom-cli をインストールしてセットアップ済みであれば soracom-cli を使ってソラカメ API を呼び出すのが一番簡単なので、この記事ではここから先の説明では soracom-cli を使います。
soracom-cli をまだインストールしていないという方は、README (英語 / 日本語) に書かれた手順にしたがってインストールし、初期設定を行ってください。
soracom-cli を使って、試しにいくつかのソラカメ API を実行してみましょう。
カメラ一覧を取得する
アカウント(SORACOM オペレーター)に登録されているカメラの一覧を取得するには、soracom sora-cam devices list コマンドを実行します。
カメラが登録済みでしたら、以下のように一覧が表示されるはずです。
$ soracom sora-cam devices list [ { "configuration": { "audioAlarmEnabled": false, "motionDetectionEnabled": true, "smokeAlarmEnabled": false }, "connected": false, "deviceCategory": "Camera", "deviceId": "7CDDxxxxxxxx", "firmwareVersion": "4.37.1.101", "lastConnectedTime": 1667896875949, "name": "ATOM Cam Swing", "productDisplayName": "ATOM Cam Swing" }, ... { "configuration": { "audioAlarmEnabled": false, "motionDetectionEnabled": true, "smokeAlarmEnabled": false }, "connected": true, "deviceCategory": "Camera", "deviceId": "7CDDxxxxxxxx", "firmwareVersion": "4.58.0.100", "lastConnectedTime": 1667971338458, "name": "ATOM Cam 2 Wood deck ", "productDisplayName": "ATOM Cam 2" } ]
常時録画データのエクスポートを開始する
クラウドに常時録画されている映像から一部を切り出してダウンロードできる形にする(=エクスポートする)には時間がかかるため、いったんエクスポート処理の開始を指示したら、あとはエクスポート処理が完了するまで定期的に処理の進捗状況をポーリングして確認する必要があります。エクスポート処理が完了すると映像データをダウンロードするための URL が入手できます。
このとき利用する API は、エクスポート処理の開始を指示する API と、エクスポート処理の進捗状況を確認する API の 2 つです。
ここではまずエクスポート処理の開始を指示する API を呼んでみましょう。
$ now="$( date +%s )"; soracom sora-cam devices videos export --device-id 7CDDxxxxxxxx --from "$(( now - 60 ))000" --to "${now}000" { "deviceId": "7CDDxxxxxxxx", "exportId": "6e061429-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "operatorId": "OP00xxxxxxxx", "requestedTime": 1668342217441, "status": "initializing" }
ちょっとコマンドが複雑なようにみえますが、順番に紐解いていきましょう。
まず now="$( date +%s )" の部分 ですが、これは now という名前の変数に、現在時刻の Unix time 表現を格納しています。
これにより、now にはたとえば 1668341455 といったような数が入ります。
続いて soracom sora-cam devices videos export コマンドを呼び出しています。こちらのコマンドの引数は --device-id --from --to の 3 つが必須です。
--device-id はカメラのデバイス ID です。先ほどカメラの一覧を取得したときに "deviceId" フィールドとして格納されていた値を使います。
--from と --to は、常時録画されている映像のどこからどこまでの区間をエクスポートするかを指示するための開始時刻と終了時刻です。
こちらの引数は、ミリ秒単位の Unix time で指定する必要があります。date コマンドで取得できる Unix time は秒単位のため 1、末尾に 000 を付与してミリ秒単位にしています。
--from "$(( now - 60 ))000" は現在時刻の 60 秒前を指定していて、--to "${now}000" は現在時刻を指定しています。したがって、現在時刻の 1 分前からの 1 分間の映像データのエクスポートを指示したことになります。
API のレスポンスには exportId や status が入っています。 exportId はエクスポートの進捗状況を確認する際に必要になりますので控えておきましょう。
エクスポート処理の進捗状況を確認する
エクスポート処理の進捗状況を確認するためには以下のコマンドを実行します。
$ soracom sora-cam devices videos get-exported --device-id 7CDDxxxxxxxx --export-id 6e061429-xxxx-xxxx-xxxx-xxxxxxxxxxxx { "deviceId": "7CDDE9028C51", "exportId": "6e061429-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "operatorId": "OP00xxxxxxxx", "requestedTime": 1668342217441, "status": "processing" }
--export-id には先ほどメモした exportId の値を指定してください。
先ほどエクスポート開始を指示した際は status が initializing でしたが、今は processing になっています。これはエクスポート処理を開始する指示が受け入れられ、エクスポート処理が実際に進行中であることを示すステータスです。
数秒おきに同じコマンドを繰り返し実行してみてください。
何度か同じ processing 状態のままレスポンスが返ってくると思いますが、そのうち以下のように status が completed となり、url フィールドが追加されるはずです。
$ soracom sora-cam devices videos get-exported --device-id 7CDDxxxxxxxx --export-id 6e061429-xxxx-xxxx-xxxx-xxxxxxxxxxxx { "deviceId": "7CDDxxxxxxxx", "expiryTime": 1668342854000, "exportId": "6e061429-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "operatorId": "OP00xxxxxxxx", "requestedTime": 1668342217441, "status": "completed", "url": "https://soracom-sora-cam-devices-api-export-file-prod.s3.amazonaws.com/2022-11-13-12-23-37_OP00xxxxxxxx_7CDDxxxxxxxx_ATOM%20Cam%202%20Wood%20deck%20_6e061429-xxxx-xxxx-xxxx-xxxxxxxxxxxx.zip?AWSAccessKeyId=ASIA...&Signature=1aqj...." }
curl コマンドなどでこの URL にアクセスすることでファイルをダウンロードすることができます。映像のフォーマットは MP4(動画は AVC/H.264 で圧縮されています)ですが、指定した期間に複数の映像が含まれる可能性があるため、zip 形式でまとめられています。(動画ファイルが一つだけでも .zip ファイルとしてダウンロードされます)
この URL には有効期限があります。有効期限はエクスポートが完了してから 10 分間です。なのでエクスポートが完了したら速やかにダウンロードを開始してください。
有効期限が切れた場合は status の値が "expired" に変化します。
静止画像データのエクスポートを開始する
ソラカメ API を使うと、動画だけでなく指定した日時の静止画像もダウンロードできます。
$ now="$( date +%s )"; soracom sora-cam devices images export --device-id 7CDDxxxxxxxx --time "$(( now - 60 ))000" { "deviceId": "7CDDxxxxxxxx", "exportId": "369b957a-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "operatorId": "OP00xxxxxxxx", "requestedTime": 1668408035409, "status": "initializing" }
映像をエクスポートしたときとの違いは、サブコマンドの一部の videos だった箇所が images に変わっていることと、引数のうち時間の範囲を指定する --from と --to の代わりにピンポイントで取得したい静止画の時刻を指定する --time に変わっていることです。
--device-id に指定している値は先ほど映像をエクスポートしたときと同じで、対象となるカメラの deviceId です。
--time に指定するタイムスタンプはミリ秒単位の Unix time なので、映像のエクスポート時と同じように現在時刻の 1 分前の Unix time(秒単位)に 000 を追加してミリ秒単位に変換しています。
静止画のエクスポートは通常はほぼ瞬時に完了しますので、以下のようにエクスポート状況を確認すると status がすでに "complete" になっていることが多いと思います。
$ soracom sora-cam devices images get-exported --device-id 7CDDxxxxxxxx --export-id 369b957a-xxxx-xxxx-xxxx-xxxxxxxxxxxx { "deviceId": "7CDDxxxxxxxx", "expiryTime": 1668408637000, "exportId": "369b957a-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "operatorId": "OP00xxxxxxxx", "requestedTime": 1668408035409, "status": "completed", "url": "https://soracom-sora-cam-devices-api-export-file-prod.s3.amazonaws.com/2022-11-14-06-40-35_OP00xxxxxxxx_7CDDxxxxxxxx_ATOM%20Cam%202%20Wood%20deck%20_369b957a-xxxx-xxxx-xxxx-xxxxxxxxxxxx.jpg?AWSAccessKeyId=ASIA...&Signature=DMeoj... }
映像のときと同じように、こちらの URL にアクセスすると静止画がダウンロードできます。(動画とは異なり、複数の画像が取得されることはありませんので zip にはなっておらず、JPEG ファイルが直接ダウンロードできます)
ここまでで、ソラカメ API を使って動画および静止画をダウンロードできるようになりました。
次はこれらの API を活用してタイムラプス映像を作っていきましょう。
タイムラプス映像とは?
最近はスマホのカメラ機能でも簡単にタイムラプスが撮影できたりすると思いますので皆さんすでにご存知だとは思いますが、一定の時間間隔で長時間にわたって写真を撮り、その写真をつなぎ合わせて映像にするというものです。空の雲が流れたり、星空がぐるっと回転していく様子がタイムラプスでダイナミックに表現された動画を皆さんも一度はご覧になったことがあるのではないでしょうか。
普段は動きや変化の少ない、でも長時間でみると確実に変わっている、そんなものを撮影して手早く確認するためにタイムラプス映像を作成することはひとつの有効な手段です。
タイムラプス映像の作り方
タイムラプス映像を作るには、大きく分けて以下の 2 つの作業が必要です。
- 一定の時間間隔で写真を撮り続ける
- それらの写真をつなぎ合わせて動画にする
実はこの 2 番めの作業に関しては、ffmpeg などのツールを使うと誰でも簡単にできてしまいます。
というわけで、タイムラプス映像を作る上でやらなければならないことは実質的には 1 番の作業です。
タイムラプス映像を作る上での困りごと
通常は「この場所のこの時間のタイムラプス映像を作りたい」と思ったら 事前に 計画を練り、撮影用の機器を設置したりといった準備を入念に行う必要があります。 たとえば、何月何日の何時から何時までの○時間分をもとに最終成果物の動画としては○秒くらいになるようにしたいと思ったら、そこから逆算して何秒間隔で何枚の写真を撮らなければいけないかということを計算して撮影する必要があります。そのパラメーターで満足の行く結果が得られるかどうかは実際に映像を作ってみないとわかりません。たとえばタイムラプス動画ができてから尺をもうちょっと長くしたいとか、もっと細かい間隔で写真を撮っておけばよかったと思っても後の祭りです。そうならないためには予定よりも短めの間隔でたくさん写真を撮っておくとか、予定の開始終了時刻に余裕をもたせておくといったことも必要になります。いずれにせよ事前に考えなければならないことが多く、私のような心配性にはとても億劫な作業になります。
ソラカメでタイムラプス映像を作ると嬉しいこと
一方ソラカメがすでに設置済みでクラウド常時録画をするように設定してあれば、動画はもう存分に存在しているわけなので、その動画を元に「あの時間帯のタイムラプス映像を作ろう」と後から思ったとしてもそれができてしまいます。パラメータの試行錯誤も比較的自由自在です。
通常のタイムラプス作成時も、最初から写真で撮るのではなく動画として撮影しておけば、そのような試行錯誤ができるかもしれません。しかし数時間にも渡る映像ファイルを取り扱うのは若干の不便が伴います。ファイルサイズが大きくなりがちですし、そもそも撮影していない時間帯の画像を使いたくなってしまったらそれはやはり不可能です。クラウドに常時録画されているというのはそういう面でとても便利です。
実は私がこの後ご紹介するサンプルのタイムラプス映像も「あの場所のあの時間帯のタイムラプス映像を作ったら面白いかもな」と後になって思って作ってみたものになります。時間帯も「たしか○月○日の午前 9 時から11時くらいの間だったかな?」というような曖昧な記憶から、試しにその前後の動画を確認して正確な開始・終了時刻を決めることができました。これは常時録画の強みですね。
ソラカメ API を使ってタイムラプス映像を作るためのスクリプト
前置きが長くなりましたが、ようやくスクリプトのご紹介です。
スクリプトの全体をここに掲載するとそれだけで結構なボリュームになってしまいますので GitHub に置きました。
スクリプトの説明
このスクリプトを実行するには ffmpeg soracom jq curl の各コマンドが必要ですので事前にインストールしておいてください。
(需要があれば、これらのコマンドやスクリプト自体を事前にインストールした Docker コンテナを作ってそれを使っていただけるようにしたりしても良いかもしれませんね)
# パラメータの設定(ご利用になる環境や目的に応じて変更してください) device_id=7CDDxxxxxxxx # => カメラのデバイス ID に置き換えてください。デバイス ID は `soracom sora-cam devices list` コマンドで取得できます。 work_dir=/tmp/sora-cam-timelapse-work # => ダウンロードした静止画ファイルを一時的に保存しておくディレクトリです。好きなディレクトリを指定してください。 now="$( date +%s )" start="$(( now - 7200 ))000" # => 開始時刻を現在時刻の 2 時間前に設定します。 end="$(( now - 3600 ))000" # => 終了時刻を現在時刻の 1 時間前に設定します。つまり、この start と end によって、現在時刻の 2 時間前から 1 時間前までの 1 時間分の映像を使ってタイムラプスを作成します。実際には好きな時間を指定してください。 # スクリプトの実行 ./sora-cam-timelapse.sh --work-dir "$work_dir" --device-id "$device_id" --start "$start" --end "$end"
スクリプトに指定するパラメータが少し多めですね。必須オプションは上で指定している 4 つです。これ以外にも指定可能なオプションがありますので、詳しいことはヘルプをご参照ください(スクリプトに引数を指定せずに実行するとヘルプが表示されます)
出来上がったタイムラプス映像
実際にこのスクリプトを使って私が作ったタイムラプス映像がこちらです。
休日にウッドデッキの汚れを高圧洗浄で落とす作業をしている最中に「この様子をタイムラプスで見たら面白そうだな?」と思って、翌日に雑なスクリプトを書いたら自分でも思っていた以上に簡単にタイムラプス映像が作れてしまいました。
みなさんもぜひソラカメ常時録画でタイムラプスを作って面白い映像が撮れたらシェアしてください!
同僚に教えてもらった Reddit Power Washing Porn
当初このタイムラプス映像は社内の Slack で仲間内だけでシェアしていたのですが、同僚のうちの一人が以下の URL を教えてくれました。
なんかわかる気がするというか、キレイになっていく様子を早送りで観察できるのは気持ちがいいですね。
新しい趣味を開拓されてしまった気分です。
(私の映像を reddit に投稿する勇気はさすがに無かったですがw)
宣伝
ところでみなさん、スクリプトの start とか end に Unix time をミリ秒単位で指定するの、なんか面倒だな〜と思いませんでしたか?
思いますよね。
私はついカッとなって github.com/bitbears-dev/dq というツールを作ってしまいました。
これを使うとたとえば以下のように比較的簡単に目的の Unix time(ミリ秒単位)を取得できます。
$ dq 'guess("2022-12-01T01:02:03Z") | .unixMilli' 1669856523000
ソラカメ API に限らず、SORACOM API は Unix time をミリ秒単位で指定しなければならない場合が多いですし、逆に API のレスポンスにミリ秒単位の Unix time が含まれていることも多いです。そんなとき簡単に Unix time と Human friendly な表記を相互変換できるのでとても便利です。
よろしかったらこちらもぜひ合わせてご利用ください。
ぼくの かんがえた さいきょうの ラズパイ クラスタ(物理(要資格 〜 その3 設計・施工編
3 回目の今回はいよいよ設計・施工を行ないます。
設計図
昨今は世界的な半導体不足の影響を受けたのか、ラズパイも手に入りにくくなってしまいましたね。
とはいえ、ラズパイクラスタを構築しようという気概をお持ちの方はすでに管理に困るくらいの数のラズパイをお持ちのはずです。今はラズパイをそんなにたくさん持っていないという方も、今から電気工事士の資格を取得したりしているうちにあっというまに半年くらい経ってしまいますので、その間に世界の半導体不足が少しは解消されたりするかもしれません(希望的観測)
ちなみに今回ご紹介する方法ですと、ラズパイに限らず Arduino や M5Stack、BeagleBone などのボードも同じ方法で整理できるというスグレモノです。
私の頭の中に妄想したラズパイクラスタの電気的な接続構成を図に起こすとこんな感じになります。 (頑張って Inkscape で書きました。本当は CAD とかが使えればもっとかっこよくて正確な図になると思いますが・・・😅)

交流部分は黒い線は L、青い線は N のラインで緑はアースです。 直流部分は赤い線が + (VCC) で黒い線が - (GND) です。 水色の線は電力の線ではなく Ethernet ケーブルです。無線 LAN でも良かったのですがなんとなく無線 LAN のセットアップが面倒なイメージがあったのと、何より DIN レールに取り付けられるスイッチングハブを使ってみたかったので有線にしてみました。
3 つのスイッチング電源の入力電流は 1.8A + 0.55A + 0.55A = 2.9A なのでブレーカーの定格電流は 3A としました。 もっとラズパイを増設したくなってスイッチング電源を増設するとしたらブレーカーも取り替えないといけませんね。
AC 100V の部分の電線は 1.6mm の VVF ケーブルを使う予定なので許容電流は 15A はあるので問題なさそうですが、直流の部分の電線はどのくらいの太さのものを用いれば良さそうでしょうか。一番電流が流れるのは 5V 10A のスイッチング電源と端子台の間ですね。 この部分の電線は、交流と見分けが付けやすいように赤黒に色付けされた VFF ビニル平型コードを用いようと思います。1.25sq 以上の太さの芯線であれば許容電流的にも大丈夫そうです。
各ラズパイへの電源はスイッチング電源から端子台を経由して GPIO ピン経由で供給します。GPIO ピンから入力すると USB の規格以上の電流を流すことができますが、電源の保護回路をバイパスしてしまうようなのでピンの接続間違いなどには十分気をつけなければなりません。 USB モデムを接続して電波状況の悪い中で通信するといったような USB 端子経由での電源供給では電力不足になるような状況であっても、GPIO からの給電であれば十分な電力供給を行うことができます。
ちなみに Raspberry Pi 4 Model B の AC アダプタの定格は 5V 3A が推奨されているようですが、ネット上の情報などによると実際に流れる電流は 1〜2 A 程度とのことです。もちろんラズパイに接続する機器によってはもっと増えたりするかもしれませんし、アダプタの負荷率や USB ケーブルでの電圧降下などを考えて余裕を見ての推奨値になっているとは思いますが、やはりラズパイ 1 台あたり 3A 程度は流せるような構成にしていきたいと思います。
まず、GPIO ピンには QI コネクタ(デュポンコネクタ)というものを使ってピンヘッダーに接続します。QI コネクタは許容電流 3A のものを入手して利用しました(たまに小型サイズのものなどは許容電流 1A というものもあるようなので要注意です)。
また、この部分に用いる電線は UL1007 規格に準拠した AWG 26 のものにしました。これであれば許容電流的にも、QI コネクタのハウジングの物理サイズ的にもちょうど良さそうです。
Arduino や M5Stack はラズパイほどの電流は流れないのでそのあたりはもう少しお気楽に設計することができます。 スイッチング電源から Arduino や M5Stack の DC 入力に供給します。DC 入力のコネクタは Amazon などで購入可能です。
なお設計・施工の際にはこの内線規程という本を熟読して(すいません、嘘つきました。900 ページ以上もあるので全てを読んで理解するのはとてつもない時間がかかりますので実際のところは関係のありそうなところをつまみ食いして)参考にしました。参考にしたというか規程に従うようにしました。致命的な見逃しや勘違いなどは無いように気をつけたつもりではありますが、もし何らかの問題にお気づきになられた場合は優しく教えていただけますと幸いです。
 第13版: JEAC 8001-2016")
この内線規程を読んでみると、電気工事士の筆記試験や技能試験で覚えたことの多くがこの本に書かれているということがわかります。 というか、逆にこの本に書かれていることのうち、本当に重要なごく一部の知識が筆記試験や技能試験で問われていたんだな、ということに気付かされます。
今後の電気工事士人生(大げさw)において重要なバイブル的な一冊になりそうです。
施工
さて、それではいよいよ施工です。
2x4 の SPF 材で枠を作り、そこに有孔ボードを固定しました。 有孔ボードに DIN レールをねじで止めて固定し、ブレーカーや端子台、スイッチング電源やスイッチングハブ、Raspberry Pi や Arduino などを配置していきます。 大まかな配置を行ったらケーブルで接続していきます。
設計図では右側の DIN レールを 3 本にしていましたが、スイッチングハブの列の DIN レールはラズパイの列の DIN レールと共用としました。
というわけで出来上がったのがこちら!



いかがでしょうか?
ちょっとラズパイの台数が少ないので若干迫力に欠ける気もしますが、今後ラズパイの台数を増やしていくにあたってもケーブル類のごちゃごちゃに悩まされずに整然と拡張していけそうな気がしませんか?
LAN ケーブルも自作してちょうどよい長さにするか、そもそも有線で接続するのはセットアップ時とか緊急時のみということにして普段は無線 LAN で接続するようにすれば、Ethernet ケーブル周りももっとすっきりできそうです。
電圧計とか電流計とかも常設したいなと考えているところです。
そんな風に夢が広がりますね😊
費用
計算するのが怖いほどお金がかかっています・・・
以下にご紹介する値段は、私の購入時の参考金額です。
まず部材編。
| 部材名 | 税込単価 | 個数 | 税込合計金額 | 備考 |
|---|---|---|---|---|
| VVF 1.6mm 3C(公団用)100m 巻 | ¥8,162 | 1 | ¥8,162 | |
| コード 1.25sq 6m 赤/黒 | ¥618 | 1 | ¥618 | |
| フェルール端子(100 個入り) | ¥2,750 | 1 | ¥2,750 | 1.25sq のコードの両端に圧着してスイッチング電源や端子台に接続しやすく |
| UL1007 AWG 26 電線 赤 10m | ¥541 | 1 | ¥541 | |
| UL1007 AWG 26 電線 黒 10m | ¥541 | 1 | ¥541 | |
| QI コネクタ(1 極 20 個入) | ¥351 | 1 | ¥351 | 端子台側に使用 |
| QI コネクタ用プラグコンタクトピン(オス)100 個入 | ¥912 | 1 | ¥912 | 端子台側に使用 |
| QI コネクタ(2x3 極 20 個入) | ¥1,099 | 1 | ¥1,099 | ラズパイ側に使用 |
| QI コネクタ用コンタクトピン(メス)100 個入 | ¥912 | 1 | ¥912 | ラズパイ側に使用 |
| DC 電源コネクタ(L 型)x 10 | ¥453 | 1 | ¥453 | |
| ラズパイ DIN レールマウント | ¥1,759 | 5 | ¥8,795 | 現在在庫切れのようです。代替品 |
| M5Stack Base15 産業用プロト基板モジュール | ¥1,309 | 1 | ¥1,309 | M5Stack を DIN レールにマウントするためのパーツが入っています |
| DIN レール 110mm | ¥1,075 | 1 | ¥1,075 | カット品なので定尺品より高いです。自分で切断できる方は定尺のものを買ったほうが安上がりだと思われます |
| DIN レール 500mm | ¥774 | 2 | ¥1,548 | |
| 端子台(AC 100V 用) | ¥2,298 | 1 | ¥2,298 | |
| 端子台(接地用) | ¥1,507 | 1 | ¥1,507 | |
| 端子台(DC 5V/12V 用) | ¥1,716 | 2 | ¥3,432 | |
| スイッチングハブ 10/100Mbps 5 ports | ¥7,678 | 1 | ¥7,678 | |
| Ethernet ケーブル 0.5m | ¥453 | 3 | ¥1,359 | |
| ブレーカー | ¥2,200 | 1 | ¥2,200 | |
| ブレーカー用端子カバー(3 個セット) | ¥782 | 1 | ¥782 | |
| スイッチング電源 5V 10A | ¥3,740 | 1 | ¥3,740 | |
| スイッチング電源 12V 1.67A | ¥2,750 | 1 | ¥2,750 | |
| スイッチング電源 24V 1.0A | ¥2,475 | 1 | ¥2,475 | |
| 小計 | ¥57,278 |
これとは別に送料がかかっています。(複数のお店で複数回購入したので送料だけで結構な金額になっていると思われます)
このリストについて少し補足しますと、まずは電線ですが、VVF 1.6mm 3C の「公団用」といわれる絶縁被覆が黒白緑に色分けされているケーブルを購入しましたが、実際には 2〜3m しか利用しないのですがこれが一巻 100m 単位でしか販売されておらず、送料も合わせて 1 万円弱かかりました。 また直流部分の電線も最終的にはここに記載した 1.25sq のコードや UL1007 の AWG 26 の電線に落ち着きましたが、線の太さなどで他にもいろいろ試行錯誤したので数千円は追加でかかっているかもしれません。
また、ここに記載したもの以外に結束バンドやネジなどは自宅にあったものを利用しました。
それから、これらの部材を取り付ける土台となる 2x4 材やシンプソン金具、有孔ボード、ボード固定用の金具などは近所のホームセンターで購入しましたがレシートを捨ててしまったので正確な費用はわかりませんが1万円くらいはかかったかなと思います。コーススレッドはもともと持っていたものを使いました。
続いて工具にかかった費用です。 意外とお金がかかるのがこちらですね。
| 部材名 | 税込単価 | 個数 | 税込合計金額 | 備考 |
|---|---|---|---|---|
| フェルール端子用圧着工具 | ¥17,785 | 1 | ¥17,785 | |
| ワイヤーストリッパー | ¥2,890 | 1 | ¥2,890 | |
| 精密圧着ペンチ | ¥3,435 | 1 | ¥3,435 | |
| 検電器 | ¥2,763 | 1 | ¥2,763 | |
| 小計 | ¥26,873 |
基本工具(ドライバー、ペンチ、プライヤー、VVF ストリッパーなど)はこの後にご紹介する資格取得費用のほうに含まれている「工具セット」のものを使いましたのでこちらには含めていません。
フェルール端子用の圧着工具は中華製のもっと安いものを一度購入したのですが、精度が全然ダメでかしめた端子が変な形になったりしてしまったので泣く泣くフェニックスコンタクト製の純正っぽい高級品を購入しました。
ワイヤーストリッパーはとてつもなく便利です。動作ギミックを見てるだけでワクワクします。 その次の精密圧着ペンチは QI コネクタの端子を圧着するための工具です。どちらも「エンジニア」という名前の会社の製品ですが、とても良いものですね。
最後は検電器です。これはまあこの規模の回路であれば無くても問題ないとは思いますがあると便利です。私はブレーカーの N の極にちゃんと中性線を入れられているかを確認するために使用しました。
このリストに上げた以外にも、2x4 材の枠を作るのに電動インパクトドライバ等を使いましたがそれらはもともと持っていたものを使用しました。 ノギスやピンセットなどもあると何かと便利だったりします。
最後に資格取得にかかった費用です。
| 費用名 | 税込単価 | 個数 | 税込合計金額 | 備考 |
|---|---|---|---|---|
| 第二種電気工事士試験受験費用 | ¥9,300 | 1 | ¥9,300 | |
| 筆記試験過去問 | ¥1,078 | 1 | ¥1,078 | |
| 電気工事士技能試験工具セット | ¥11,483 | 1 | ¥11,483 | |
| 第二種電気工事士技能試験 練習用部材 | ¥16,715 | 1 | ¥16,715 | |
| 免状発行用収入証紙 | ¥5,300 | 1 | ¥5,300 | |
| 小計 | ¥43,876 |
あとは細かいですがこれら以外にも試験会場を往復するための交通費や、複線図を書くのに便利なフリクションの 3 色ボールペンなども購入しました。
というわけで、新たに支出した分だけでも総額 13 万円近くかかった計算になりますね・・・😓 (試行錯誤した分も含めるとゆうに15万円は超えているかな)
あなたもラズパイクラスタを構築してみては?
電線などの部材はたくさん余っているし、工具も一通り買い揃えましたので本当は「私が作ってあげましょう!(有料で)」と言いたいところなのですが、そうするためには電気工事業法で定めるところの電気工事業者にならないといけなさそうで、そうなるためには最低 3 年間の実務経験が必要なのであった...。(電気工事業者になるには主任電気工事士という人を設定しなければならず、その人になるためには第一種電気工事士の資格を取るか第二種電気工事士になって 3 年の実務経験を積む必要があり、第一種電気工事士になるにも 3 年の実務経験が必要なのでいずれにせよ 3 年の実務経験が必要なようです。)
無償でならいいのかもしれませんが私もそんなに暇ではないですしやるからにはそれなりの対価は欲しいですしね😂
というわけで、みなさんも自分でがんばって「さいきょうの ラズパイ クラスタ」作ってみてくださいね!
ぼくの かんがえた さいきょうの ラズパイ クラスタ(物理(要資格 〜その2 資格取得編
その1 からの続きです。
電気工事士資格
妄想に任せて設計図面(と呼べるようなちゃんとしたものではないですが)を描いたりしていたとき、ふと 「スイッチング電源って、交流 100V の電源を入力するけど、コンセントにプラグを差し込んだりするだけの気軽な感じじゃなくて、電線をネジ止めしたりしないといけなさそうな気がするな?それってなんか資格持ってないとやっちゃいけないんじゃなかったっけ?」 という考えが頭をよぎりました。
少し調べると、どうやら「電気工事士」という資格が必要そうです。
電気工事士法やその施行規則を確認しますと、電気工事士の資格を持っていないとやってはいけない作業が定められています。 その中でも、電気工事士法施行規則に書かれている作業のうち、以下のような作業は実施しそうな感じがします・・・
イ 電線相互を接続する作業
:
ハ 電線を直接造営材その他の物件(がいしを除く。)に取り付け、又はこれを取り外す作業
:
ホ 配線器具を造営材その他の物件に取り付け、若しくはこれを取り外し、又はこれに電線を接続する作業
造営材というのは、平たく言うと家の壁や柱などのことです。配線器具とは、コンセントやスイッチのようなものです。
DIN レールを壁などどこかに固定し、その DIN レールにスイッチング電源や端子台、ラズパイなどを取り付けてそれらを電線で接続する作業は「ホ」に該当しそうな感じがします。
電線も宙ぶらりんは良くなさそうですので「ハ」の作業を実施するかもしれません。
電線同士を圧着したりして接続するような「イ」の作業はしなさそうな気もしますが、自分自身の安全のためにも、今後もっと高度な作業をしたくなった場合のことを考えても資格を持っておいて損はないだろうということで第二種電気工事士の資格を取ることにしました。自宅の外構部などに電灯やスイッチ類を増設したりしたいとも考えていたところでしたので、それももしかしたら自分でできるようになるかもしれません。
調べたところ、電気工事士の試験は年2回行われているようです。
電気工事士には「第一種」と「第二種」がありますが、自宅で 100V 程度の電圧を扱うのでよければ「第二種」で十分なようです。
試験は筆記試験と技能試験の2段階になっているようで、筆記試験の合格者が技能試験を受けることができます。
試験を実施している一般財団法人電気技術者試験センターのサイトで過去問が公開されているので見てみました。
電気工学、電磁気学などについては学生時代に学んでいましたので、電気の理論については過去問で練習すれば大体できそうな感じがしたのですが、それ以外の工事に関する知識がほとんどなく、これは難しそうだなと思いつつも、筆記試験は 60 点以上取れば(50問中30問正答すれば)合格するようでしたし、技能試験は事前に公表された 13 問のうちのいずれか 1 問が出題されるということで、事前にしっかり練習すれば大丈夫だろうと考えましたので頑張ってみることにしました。
インターネットで早速受験の申込みをしました。受験の申込時に支払った費用は 1 万円弱でしたが、教材(特に技能試験で使う工具や練習用の材料)や手袋などの作業用の道具、過去問の問題集、受験時の交通費、合格後にかかる費用なども合わせると合計で 4〜5 万円くらいはかかると思っておいたほうが良さそうです。
日本エネルギー管理センター事務局さんが公開されている YouTube のプレイリストで勉強させていただきました。 すごくわかりやすくて良かったです。
YouTube で動画を見て、過去問をやってという感じで 1 ヶ月半くらい勉強しました。
筆記試験
いよいよ試験当日です。
受験票のハガキに記載されている会場まで、公共交通機関を利用して移動しました。 私はとある私立大学が会場として指定されましたが、大学の最寄りの駅から臨時のバスが出ていて、大勢の受験者を運んでいました。
大学に着くと、受験番号に応じてどの教室に行けばよいかという情報が記載された紙が、大学の入口付近で配られました。
開場時刻の少し前に教室の前に到着したので、廊下でしばらく待ちました。
教室が開けられ、自分の席に名前と受験番号が書かれたシールが貼られているのを確認して着席しました。
筆記用具などを机の上に出しておき、試験開始時刻を待ちました。
試験監督の方から説明などがあり、ようやく試験開始。
試験は全部で 2 時間弱の時間が取られていたと思いますが、試験開始から半分くらいの時間が経過すると途中退出が可能になったと記憶しています。
私は途中退出が可能になった時刻にはすべての問題を解き終えていましたが、念のためもう一度すべての問題を見直して、1 問だけ回答を変えてから提出して退出しました。
行きのバスが混みすぎていたので帰りは駅まで歩こうと心に決めていました。30 分ほど歩いて駅まで戻りました。
試験の翌日には解答が公表されましたので自己採点してみたところ 50 問中 48 問正解でした。間違えた 2 問のうちの 1 問はうっかりミスで、問題文をよく読み直したら正解できていました。もう 1 問は最後に見直して回答を変えてしまったところでした。回答を変える前は合っていたのに変えてしまったことで間違ってしまったので惜しいことをしたなぁと思いましたが、いずれにせよボーダーラインは大きく超えているようでしたので安心しました。
この日から、次の技能試験の対策を開始しました。
技能試験の練習
技能試験も日本エネルギー管理センター様の公開されている YouTube のプレイリストを 1 から順番に見ていきながら、実際に自分でも回路を作ってみるという作業を繰り返して練習しました。
練習用の部材は以下のようなセットを買うと一式揃いますので、私のような右も左もわからなかったような初心者にはちょうど良かったです。ただ、たとえばランプレセプタクルは公表問題13問中12問で使われていますがこのセットには 1 つしか入っていません。ですので各問題を練習し終わる度にランプレセプタクルなどの部材を取り外して次の問題の練習に再利用するというようなやり方になります。ただ、ランプレセプタクルが 12 個もあっても置き場所に困るでしょうし、それでよいとは思います。差し込み型コネクタも最低限の数しか入っていないので、基本的には再利用しながら練習していく感じになると思います。
 令和4年 第二種電気工事士技能試験 練習用部材 DK-51 1回セット ハンドブック付")
工具もホーザン様の出されているセットを購入しました。日本エネルギー管理センター様の動画の中で使われているのと同じ工具のセットですし、実際に資格取得後にも普通に使えそうなので、私のような初心者にはちょうど良いと思います。
 電気工事士技能試験工具セット 基本工具+P-958VVFストリッパー DK-28 ハンドブック付")
動画を見たあとに実際に自分で回路を作ってみると、思ったよりも時間がかかることがわかります。 実際の試験では 40 分間で回路を完成させなければなりませんが、かなりテキパキやったつもりでも 35 分以上かかっていたりします。 もし本番でどこか少しでも間違えたりすると、やり直す時間はほとんどないのではないかと心配になります。 特に電線の圧着や差し込み型コネクタへの差し込みを間違えるとやり直しはかなり難しそうです。 また、複線図を書いている時間も無さそうなので 3 路 / 4 路スイッチのある回路などはスラスラと接続できるかどうか心配になります。 ただ、13 問もある公表問題を 1 つずつ練習していくにつれてだんだんとコツを掴むことができましたので、10 問くらいを練習した時点では時間に余裕もできるようになってきました。自分がミスしやすいポイントなどにも気付けるので、最低でも各問一回ずつは練習したほうがよいでしょう。
あと、素手で作業していると VVF のシースを剥いたりする作業で思いのほか指にダメージがあります。 私はホームセンターで軽作業用の手袋を購入して使用しました。
ついでにホームセンターでいままであまり寄り付いたことのなかった電気工事関連のコーナーを見てみたところ、VVF ケーブルや圧着コネクタ、差し込み型コネクタなど必要そうなものがすべて売られていましたので、もし公表問題の練習が 1 回ずつだけだと不安で 2 回めの練習をしたくなったとしてもここで部材を買い揃えることができそうだということがわかりました。
筆記試験からおよそ 1 ヶ月経ったころ、技能試験の受験票が届きました。筆記試験に合格した旨はそのハガキの中に小さく書かれていて、こんなものかと思いました。
技能試験当日
筆記試験とは別の会場でしたが、こちらもやはり私立大学の教室が会場でした。 今回の会場は最寄りの駅から徒歩で行くことができる近さでした。
教室に入るまでは筆記試験のときと大体同じでしたが、説明開始時刻になってからの雰囲気が筆記試験とはだいぶ違いました。 最初に問題用紙が配られましたが、その時点では表紙しか見てはいけないというのは筆記試験と同じです。表紙には材料の一覧が書かれています。 続いて、ダンボール箱に入った材料が配られます。配られても、指示があるまで箱を開けてはいけません。 全員に行き渡っているかどうか、何度も確認が行われました。
試験開始まであと 10 分くらいといったところでようやく箱を開ける許可が出て、材料が揃っているかどうかの確認を行ないました。 電線の長さを測るのに工具が使えません(メジャーなどは使えます)。練習のときはストリッパーに付いている目盛りを使って長さを図っていましたがそれは使えないので、ホーザンの工具セットに入っていた布尺を初めて使いました(笑)
材料の確認を終えてしばらく待っていると時間になり、そのまま試験が始まりました。
私は今回は公表問題の 6 番、露出型コンセントと 3 路スイッチのある回路でした。
露出型コンセントの出来に少し不安はありましたが、一応欠陥ではないはずです。そしてそれ以外は特に問題なく完成させられました。 しかし、これまで YouTube を見て独学で練習してきただけで第三者に判定してもらったことは無かったので自分としては問題ないと思っていても試験官には欠陥と判定されてしまうのではないかという不安は試験終了後もずっとつきまといました。
技能試験結果発表
年が明けて 1 月の末、いよいよ結果が発表される日がやってきました。 当日は午前 9 時 30 分ころから試験センターのホームページ上で番号が検索できるようになるということで、事前に受験番号を準備しておきました。発表の数日前に見てみたところ、合格者一覧から自分の番号を検索すること自体はできるようになっていたので、試しに検索してみましたが当然ながら番号は見つからない旨が表示されました。
なお、自分の受験票を見て手で写すと間違えるかもしれないと思ったので、試験の申し込みのときに使ったマイページから受験番号を見つけてコピーして使用したのですが、その受験番号の記載されている場所がすごく分かりづらかったです。まず、メインのメニューから「試験申し込み」を選択しなければいけません。さらにそのページから「試験会場案内」のボタンを押して表示される画面に受験番号があります。 普通こんなところに自分の受験番号があるとは思わないと思うので、これは改善を求めたいですね。
発表当日、9 時 30 分より少し前に私の番号を検索してみたら「合格者一覧にあります」と表示されました!
あとはハガキで正式な通知が来て免状の申請を行う必要がありますが、もうこの時点ですごくわくわくしながら「ぼくの かんがえた さいきょうの ラズパイ クラスタ」の構成を図面に起こしてみたり必要な部材を Web で探してみたりホームセンターをめぐってみたりし始めました。
免状の申請
試験に合格したら、いよいよ免状の申請です。免状を所持していないと電気工事を行ってはいけないので、さっそく電気工事をしたいというはやる気持ちを押さえて必要な書類を揃えます。
正確な情報は居住都道府県の免状窓口となる団体のホームページ等を参照していただきたいのですが、私の場合は以下のものを用意する必要がありました。
- 電気工事士免状交付申請書
- 合格通知のハガキの原本
- 住民票
- 写真 (4cm x 3cm) x 2 枚
- 都道府県の収入証紙(国の発行する収入 印 紙ではないので郵便局とかでは買えません。市町村の発行する収入証紙でもない)
- 返信(免状送付)用封筒(切手なし)
郵送でも申請が可能ですが、たまたま居住している市に窓口となる団体の建物があり、しかも都道府県の収入証紙を購入できる場所が限られていて自宅から最も近い場所がその免状窓口だったので、直接赴いて申請しに行きました。
こういった外郭団体的な組織の事務所では引退間近のおっさんがめんどくさそう&上から目線で応対してそうな昭和なイメージを勝手に持っていましたが、実際に窓口に出向いてみると全くそんなことはなく、清潔感のある事務所で女性のスタッフ 3 名が働いており、とても丁寧に感じよく対応していただきました。
2 週間ほどで免状が届くとのことでしたので、それを楽しみに待ちながら「ぼくの かんがえた さいきょうの ラズパイ クラスタ」の設計をしたり部材の発注をしたりしていました。
免状が届いた!
申請を行ってからちょうど一週間後、書留で免状が届きました。窓口では 2 週間くらいと言われていたので、思っていたより早く届きました。 窓口の方は余裕を見て 2 週間とおっしゃっていたのでしょうね。
というわけで、これでいつでも電気工事を行うことができます。
いよいよ「ぼくの かんがえた さいきょうの ラズパイ クラスタ」の施工に入っていきたいと思います。
その 3 へつづく
ぼくの かんがえた さいきょうの ラズパイ クラスタ(物理(要資格 〜 その1 構想編
仕事だったり趣味だったりでラズパイやら Arduino やら M5Stack やらをたくさん稼働させている人も多いと思います。 私もそうです。
常時稼働させる台数が増えてくると AC アダプタやら USB ケーブルやら LAN ケーブルやらでごちゃごちゃになりがちですよね。 ラズパイクラスタを稼働させていたり、Arduino や M5Stack などを使っていろいろなプロトタイピングを並行して行っていたりするときっとみなさんも同じようなお悩みを抱えていらっしゃるのではないでしょうか。
そんなお悩みを解決するべく、こんな感じのものを作ってみました。
なんでこんなものを作ろうと思ったか、どうやって作ったか、作るまでの紆余曲折などを(だいぶ長くなりますが)説明してみたいと思います。
そんな話には興味はない、ラズパイクラスタをもっと詳しく見せろ、という方は その 3 へ一気に進んでください。
ラズパイタワーの弱点
私が勤めている会社の運用チームでは「ラズパイタワー」なるものを作って運用していて、日々ネットワークの監視やサービスの正常性の確認に役立っています。
個人でも自宅用にラズパイタワーを作って Kubernetes やろうかなーとか思ったこともあったんですが、ラズパイタワーにはいくつか問題がありました。
中でも個人的に懸念したことのトップ 3 が以下の通りです。
電源まわりがカオスになる
- AC アダプタがでかくて邪魔
- ケーブル類の長さが中途半端だったりして持て余してごちゃごちゃになりがち
USB からの電源供給だと電力不足になりがち
- タワー状に積み重ねると放熱が心配
放熱に関しては、なるべくならラズパイが水平方向に並ぶ状態(ラズパイ自体は平置きじゃなくても良い)がいいなぁと思っていました。(つまり下の図の左側ではなくて右側の状態)
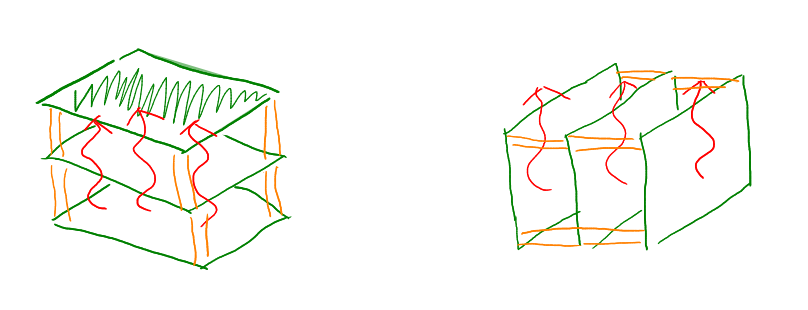
Kiskstarter で見つけた CloverPI
そんなある日私は CloverPI というプロジェクトを Kickstarter で見つけて喜び勇んで Back しました。
電源ケーブルと Ethernet ケーブルそれぞれ 1 本ずつで 4 台の Raspberry Pi を動かすことができます。 これはスマートだと思いました。
・・・しかし、CloverPI の出荷が始まったという知らせを受けた直後くらいに、CloverPI を受け取って動作確認を行ったユーザーから「基板の電源周りから出火した」という問題が報告され、それ以降 Creator による更新が途絶えてしまい、連絡がつかなくなってしまったのです・・・
私の手元にはまだ現物は届いていません。😭
Turing Pi
その後私は Turing Pi という製品も見つけました。
これは Raspberry Pi Compute Module を使ってクラスタを構築するものです。 既に持っている Raspberry Pi を搭載させることはできませんが、今後購入する Raspberry Pi をすべて Compute Module にすればよいので次善の策かとも思いました。USB も(7 台中 4 台は)使うことができそうですので、USB タイプの LTE モデムを接続したりもできそうです。
Turing Pi は ITX マザーボードと同じサイズのようなので ITX 用ケースに入れられそうなのも魅力的でした。
私の心は半分くらい Turing Pi を購入する方向に傾きかけていて、ITX のケースや電源を Amazon で探したりしていました。
DIN レール
調べていくと、ITX ケースの中には、DIN レールというものにマウントすることができるものもあるようだということを知りました。
このときの私は恥ずかしながら DIN レールというものを知らなかったのですが、調べてみるとなかなか便利そうです。
さらに調べていくと、DIN レールにマウントできるスイッチングハブなんかもあるようです。
ラズパイを DIN レールに直接マウントするマウンタも Amazon で見つけました。このマウンタ、実は Arduino UNO / Mega 等や BeagleBone などもマウントすることができます。

Web で検索してみると DIN レールにマウントできるスイッチング電源もたくさん種類があることがわかりましたので、それを使えば AC アダプタでテーブルタップまわりがごっちゃごちゃという状態も避けられるんじゃないかと思いました。(そのかわり電源ケーブルは自分で配線しなければならなくなりますが)
スイッチング電源の容量を大きいものにすれば、1 台のスイッチング電源で 3〜4 台のラズパイを駆動することも造作無さそうです。 さっと探してみた感じ、DC 5V / 10A で出力できるスイッチング電源が 3,000 円 〜 4,000 円くらいで購入できそうでした。 Raspberry Pi 4B では、5V / 3A 出力できる USB アダプタが必要ですがこれをラズパイの台数分そろえることを考えたら少し安い印象です。
ここまできたらもう私の心はスイッチング電源、スイッチングハブ、ラズパイをそれぞれ DIN レールにマウントして理想のラズパイクラスタを作るという妄想でいっぱいになりました。
Ubuntu 20.04 で GUI 起動時に任意のプログラムを実行したい
表題の件ですが、簡単だろうと思っていたら意外とハマったのでメモしておきます。
まず前提条件の整理から。
自宅で仕事用に使っている Ubuntu Desktop 20.04 で、GUI にログインした直後に実行したいプログラムがありました。
仮想マシンとか WSL のような環境ではなく、ベアメタルにインストールされている以下のような環境です。
$ uname -a Linux ogubuntu 5.4.0-94-generic #106-Ubuntu SMP Thu Jan 6 23:58:14 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.3 LTS Release: 20.04 Codename: focal
GUI にログインした直後に実行したいプログラムは具体的には xmodmap です。
以下の記事で説明しているような方法で、キーバインドの入れ替えを行ないたいのです。
Ubuntu 起動直後に xmodmap コマンドを実行して自分好みのキーバインドを適用したいというシンプルな要求があったのですが、当然 .bashrc などに書いてもその要求は叶いません。おそらく GUI のシステムの起動時に実行されるスクリプトがあるはずだろうと思っていろいろ調べたのですが、「そもそも今の Ubuntu って X Window なの?なんか Wayland?とかいうのがあるらしいけど・・・」とかそのあたりから知識が足りません。
それでもなんとか以下のような Stack Exchange の質問にたどり着きました。
どうやら GUI 起動時に読み込まれそうなスクリプトとしては .xinitirc .xsession .xsessionrc などがありそうだということがわかりました。
そこで以下のようなスクリプトを書いてみました。
$ cat ~/.xinitrc
(
if [ -s ~/.Xmodmap ]; then
/usr/bin/xmodmap ~/.Xmodmap
fi
) >~/.xinitrc.log 2>&1
(↑は .xinitrc の例ですが、.xsession や .xsessionrc も同様の内容で作成しました。)
結果として、.xinitrc と .xsession は実行されず、 .xsessionrc は実行されるのですが xmodmap コマンドがエラーを起こすという状況でした。エラーメッセージの内容的には、bad keysym in remove modifier list 'Alt_R', no corresponding keycodes といったようなもので、存在しているはずのキーコードが存在しないと言われているのでちょっとよくわからない感じです。
同じコマンドを、起動後に手で実行するとこのようなエラーは発生しないのでちょっと実行されるタイミングが早すぎたりするような感じなのでしょうか。
他に、.xprofile というファイルも実行されるらしいことがわかりましたので同様に試してみたのですが、こちらは実行されて xmodmap コマンドも正常に実行されるようでしたが、なぜかログイン後の GUI 環境では xmodmap の効果が現れません。(つまりキーの入れ替えが行われていない状態)
ちょっとどういうことなのかよくわかりません。
ほかに有力な情報も見つかりませんでしたし、不便だなとは思いつつ Ubuntu を起動する度に真っ先に Terminal を立ち上げて xmodmap コマンドを実行することでなんとかしのいでいました。
再起動なんて月に 1〜2 回くらいしかしないので仕方ないと思いながらすでに何年も経ってしまっていたのですが、やはり毎回同じコマンドを手で入力し続けるのはさすがにプログラマとしての名がすたると思って更に調べていくと以下のような情報を見つけました。
GNOME を利用している場合は $HOME/.config/autostart/ に .desktop という拡張子を持つファイルを作り、その中に 仕様 に従って設定を書けば起動時に実行されるらしいということがわかりました。
たしかに $HOME/.config/autostart/ 以下には起動時に自動的に実行されるアプリの名前が並んでいました。
試しに $HOME/.config/autostart/ に xmodmap.desktop という名前で以下のようなファイルを置いてみました。
[Desktop Entry] Name=run xmodmap at startup Exec=xmodmap /home/bearmini/.Xmodmap Type=Application
恐る恐る Ubuntu を再起動してみると・・・ログイン直後から xmodmap が実行された状態になっています!
やりました!
一応ファイルの中身を説明すると、
Name はアプリケーションの名前です。一般に公開するアプリというわけではないので自分でわかる名前を付けましょう。一応 GNOME Tweak Tool の Startup Applications の一覧に表示されるときに使われる名前になります。
Exec は実行されるコマンドと引数です。ここでは直接 xmodmap コマンドを実行していますが、複雑な処理をしたい場合はスクリプトを用意してそれを実行するようにすると良いかもしれません。
Type は Application Link Directory のうちのいずれかを指定するようで必須のフィールドですが、 Link と Directory はよくわからないのでおそらく Application でよいでしょう。
たったこれだけの記述で自動実行できるようになっただなんて・・・これまでの数年間、Ubuntu を起動するたびに xmodmap コマンドを手で実行していた自分が馬鹿らしくなりました。
復刻版: 超初心者のための Unicode(ユニコード) 入門
優秀なエンジニアであっても、これまであまり直接関わってこなかった場合、案外文字コードのことについて詳しくは知らなかったりするものです。Unicode って何?UTF-8/16/32 の違いを説明できる?サロゲートペアって何?絵文字を UTF-8 で表現すると何バイトになる?そういった質問に自信を持って答えられるというエンジニアは実はそれほど多くなかったりするのではないでしょうか。
先日、Slack 上での同僚との会話の中から、
👨👩👧👦
という絵文字が UTF-8 で何バイトか?という話題になり、調べてみたところ 25 バイトという結論になりました。
確かめてみるには、
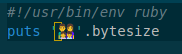
このようなコードを UTF-8 で emoji.rb というファイルに保存して、これを実行すると、
$ ruby emoji.rb 25
このような結果になります。
なぜそうなるのかを同僚には簡単に説明しましたが、Unicode とか UTF とか UCS といったような言葉の意味だったり、ほかにも様々な概念を正確に把握していないと、正しく理解することが難しいようでした。
ちなみに上記の絵文字は
- 男性の顔
- 女性の顔
- 女の子の顔
- 男の子の顔
の 4 つの絵文字を、Zero width joiner という特殊な符号で連結して一つの「家族(男性・女性・女の子・男の子)」という絵文字として扱っているという特殊なパターンです。
少し脇道にそれますと、「家族」を表す絵文字はこれだけではなく、両親が同性のパターンや片親のパターンも絵文字として存在しています。子どもも男の子 x 2 の場合や女の子 x 2 の場合、男の子か女の子が 1 人だけの場合も存在します。さらに特殊な符号を使うことで skin-tone(肌の色味)の指定も可能ですので、膨大な組み合わせを表現可能です。子どもの人数が 3 人以上の場合には今のところ対応していないようですが、1文字分のスペースにあまり詰め込みすぎても絵文字として見づらくなってしまうのでそこは仕方ないかなと思います。 いずれにせよ、それらの組み合わせ一つ一つにユニークなコードポイントを割り当ててしまうとキリがないので、基本となるパーツの組み合わせで絵文字が生成できるようになっているんですね。
そんな話をしたときに、ずっと昔に自分が書いた「超初心者のための Unicode(ユニコード)入門」というブログ記事のことを思い出しました。
当時(2006 年ころから 2010 年くらいまで)はブログシステムを自分で作っていて、レンタルサーバー(というか VPS)の上でホストしていたのでした。ブログ記事もブログシステムも更新しなくなってしまってドメイン名を expire させてしまったのと同時にそのシステムも撤収してしまったのでいまはその記事を読むことはできないのですが、今あの記事があったら同僚にも紹介できるし、もしかしたら今でもあの記事に少しは価値があって PV が稼げるかもしれないのになぁと思っていました。
そこで、ダメ元で Internet Archive で検索してみたところなんとその当時の記事が残っていました!
そんなわけでこの記事は当時の自分の書いた記事をサルベージして再掲するものです。
Internet Archive (Wayback Machine) には少しばかりですが寄付をしておきました。
では、復刻版の「超初心者のための Unicode(ユニコード)入門」、今となってはちょっと古くさく感じられる記述もあるかもしれませんが、そういうところまで含めてお楽しみください!
超初心者のための Unicode(ユニコード)入門
はじめに
XML ファイルの先頭(XML 宣言)にはとりあえず encoding="utf-8" って書いてみたり、C++ で Windows プログラムを書くときはなんとなく TCHAR とかを使ってみたり、「なんか Java とか C# とかは内部でユニコード使ってるらしいぞ」ということは知っていても実はそれがどういう意味なのかよくわかっていなかったり、「そろそろちゃんと Unicode を勉強しないといけないかな・・・でも、ネットで検索しても小難しい記事しか見つからなくてよくわかんないんだよな~」と思っていたりするそこのアナタ!
ていうか私自身が Joel on Software を読むまでその状態でした。Unicode のことをよく理解できていなかったというか、むしろ激しく誤解していました。
ただ、それは平易な日本語で書かれた Unicode 入門記事がネットに転がっていなかったからだと思います。(責任転嫁)
でも、大丈夫です。
Joel on Software にも書かれているとおり、
「Unicode はそんなに難しくない」
のです。
以下に示す、基本的な事実だけまずはおさえておけば、小難しい理屈やら歴史的事情やらは置いておいて、Unicode のことを理解できるはずです。
※ Unicode に詳しい方へのお願い
以下の文章は、厳密には間違いを含んでいるところがあるかもしれません。私自身、Unicode 初心者には変わりありませんので。もし、著しく事実と異なるような内容がありましたら遠慮なく指摘してください。
※ それから、Joel on Software を読んで Unicode に開眼したという筆者の個人的体験により、以下の文章の内容に 「Joel on Software のパクリじゃねーの?」 というものが含まれてしまうかもしれません。
著作権的に問題がありそうな点がありましたら、遠慮なく指摘してください。
それでは、超初心者のための Unicode 入門、始まり始まり~
Unicode = 文字集合
Unicode 入門といいつつ、ここでまず、Unicode のことはしばし忘れて、概念的なことを考えてみましょう。
仮に、あなたが出版社かどこかに勤めていたとして、上司から「今度わが社で "世界の文字字典(完全版)" を作ることになったので、世界中のありとあらゆる文字を全部集めて来なさい」と指示されたとします。
日本語と中国語で似てる漢字は同じ文字とするのか?とか、旧字は常用漢字と同じ文字とみなすのか?とか、全角数字の4と半角数字の 4 は同じ文字なのか違う文字なのか?とか、そういう難しいことはエライ人たちに任せるとして、あなたはとにかく文字という文字を世界中から手当たり次第に集め尽くしたとします。
そうやって集められた文字のことを、文字集合と呼びます。
そして、実はこの文字集合を作るという作業を公共的な機関で正式に行ったものが Unicode なのです。
Unicode は、文字をひたすら集めたもの=文字集合なのです。
ここで大事なのは、この時点では UTF- なんとかとか、サロゲートペアとか、意味不明な用語がまだ出てきていないということです。それらは、Unicode に含まれる文字をコンピュータ上でどう表現するかといった話なので、分けて考えましょう。
大前提として、「Unicode とはコンピュータ上の表現を離れた論理的な文字体系のことなのだ」と理解すると、それ以外の難しい話題も、もつれた糸がほどけるように徐々に理解できるようになっていくはずです。
コードポイント=文字の通し番号
文字を集めるだけ集めたら、その文字一つ一つにユニークな通し番号を付けたくなるというものです。(その理由としては、たとえば管理上便利だからとかいろいろあると思います)
Unicode でも文字に通し番号を割り当てていて、その通し番号のことをコードポイントと呼びます。
たとえば、アルファベットの 'A' は 65 番目(16進数で 0x41 番目) で、ひらがなの 'あ' は 12354 番目(16進数で 0x3042番目)です。
これらをそれぞれ U+0041 とか U+3042 と表記します。(U+ のあとに 16 進数 4 桁~ 6 桁くらいで表記します)
エンコーディング
ここでようやく、このコードポイントをどうやってコンピュータ上で扱うかという話になります。
たとえば、あなたが "こんにちは" という文字列を電子メールで送信したい場合、相手にどのようなバイナリデータを送信すればよいのでしょうか?
(メールのプロトコルとか難しいことはとりあえずひとまず置いといて。)
それぞれの文字のコードポイントは以下のように決められています。
| 文字 | コードポイント |
|---|---|
| こ | U+3053 |
| ん | U+3093 |
| に | U+306B |
| ち | U+3061 |
| は | U+306F |
(unicode.org の Unihan Database を参照しました)
各文字のコードポイントは、16 進数で 4 桁ずつなので、16bit で
3053 3093 306B 3061 306F
というデータを送ればよいような気がします。
リトルエンディアンな環境だと、バイトオーダーを入れ替えて
5330 9330 6B30 6130 6F30
というデータを送ったほうがよいかもしれません。
このように、コードポイントをコンピュータで扱えるバイト列に変換すること、またはその変換規則を「エンコーディング」と呼びます。
エンコーディングには、UTF-8, UTF-16, UTF-32 などいくつかの方法があります。
UTF-16
そして、実は、上記のように単純に 16 bit 単位に変換する方法こそが UTF-16 というエンコーディング(の一部)なのです。
リトルエンディアンのものを UTF-16 LE、ビッグエンディアンのものを UTF-16 BE と呼んだりします。
しかし、現在の Unicode は、U+10FFFF(16 進数で 6 桁)までコードポイントを定義している(それだけたくさんの文字を集めて、文字集合が大きくなった)ので、この単純な方法だと破たんしてしまいます。
この対策としてサロゲートペアという方法が出てきます。16bit のバイナリを二つ組み合わせて U+FFFF より大きいコードポイントを表現する方法です。
これについては、ちゃんと詳しく説明してくれている書籍やサイトがたくさんあると思うのでここでは割愛します。
それから、受け取り手の立場になると、UTF-16 は UTF-16 でも、リトルエンディアンで送られてきたデータなのかビッグエンディアンで送られてきたデータなのかを識別したいですよね。
たとえば、先ほどの 'こんにちは' のデータを受け取った側が、事前にビッグエンディアンで送られてくるのかリトルエンディアンで送られてくるのかがわかっていなければ、3053 というデータが U+3053 のことなのか、それとも U+5330 のことなのかわかりませんね。
そのような時に、データの先頭にバイトオーダーマーク(Byte Order Mark: BOM)を入れることがあります。
BOM は U+FEFF というコードポイントが割り当てられています。(大文字だと E と F が識別しづらいですが、小文字で書くと、U+ f e f f です)
さきほどの 'こんにちは' の前に BOM をつけると、
ビッグエンディアンなら:
FEFF 3053 3093 306B 3061 306F
リトルエンディアンなら:
FFFE 5330 9330 6B30 6130 6F30
となります。
リトルエンディアンの時に出てくる FFFE というバイナリですが、U+FFFE というコードポイントは Unicode では未定義とされていますので、U+FFFE ではなく U+FEFF (BOM)がリトルエンディアンで送られてきているのだと判断できます。
というわけで、受け取った側は最初の 16bit を読んで FEFF ならビッグエンディアン、FFFE ならリトルエンディアンと判断できるわけです。
注意点としては、データに BOM をつけたら UTF-16 LE とか UTF-16 BE とは呼ばず、単に UTF-16 と呼ばなければならないということが挙げられます。
逆に、UTF-16 LE とか UTF-16 BE とか書いたら、データに BOM をつけてはいけないということになっています。
UTF-8
今度は "Hello" という文字列を UTF-16 で表現するとしたらどうなるでしょうか?
文字 コードポイント H U+0048 e U+0065 l U+006C l U+006C o U+006F
ビッグエンディアンだと
0048 0065 006C 006C 006F
ですし、リトルエンディアンだと
4800 6500 6C00 6C00 6F00
となるでしょう。
でもこれだとなんだか 00 が途中にたくさん入っているのでもったいないですね。
特に、普段アルファベットしか使わないアメリカなど英語圏の人々にとっては、この 0 はとても余計なものに見えることでしょう。
そこで、あるルールにのっとって、アルファベットは 1 バイトで、それ以外の文字(漢字など)は 2 バイト~ 6 バイトくらいのデータに変換してバイナリにする変換規則(エンコーディング)も考えられました。
たとえばひらがなの 'あ' (U+3042) は E3 81 82 という 3 バイトに変換されます。
漢字や仮名をたくさん使う日本人にとっては、一つの文字が 3 バイト以上になってしまうのは記憶容量の無駄のようにも思えますが、UTF-8 にはもちろんメリットもいくつかあります。
たとえば、変換後のバイト列の中に0が全く現れないので、従来のヌル終端文字列用の処理(文字列のコピーなど)がうまく動く場合が多いというメリットがあります。
それから、バイトオーダーの問題がなくなります。
変換ルールがちゃんと考えられているので、文字と文字の境目がわかりやすくなっています。
また、'/' などの記号のコードが途中に表れないようになっているので、ファイル名やディレクトリ名として安全に使えます。
これらのメリットから、通信や記録の際には UTF-8 が使われることが多いようです。
UTF-8 にはバイトオーダーの問題がないのですが、UTF-8 でエンコーディングされている、ということ自体を示すために、U+FEFF (BOM) を UTF-8 の規則で変換した EF BB BF という 3 バイトを先頭につけることがあります。
つまり、テキスト処理をするプログラムが先頭の 3 バイトを読んでみて EF BB BF だったら UTF-8 の可能性が高い、と判断できるわけです。
BOM 付きの場合単に UTF-8 と呼び、BOM なしの場合 UTF-8N と呼びます。
それから、UTF-8 の変換規則は、現在の Unicode よりも大きな文字集合である 'UCS4' の範囲のすべての文字を表すことができるというのも特徴です。
(UTF-16 はサロゲートペアを使っても U+10FFFF より大きなコードポイントを表現できないが、UTF-8 なら U+7FFFFFFF まで表現可能)
UTF-32
コードポイントを固定長で表現できるような簡単な方法もあるとうれしいですよね。各文字が固定長のバイナリに変換されると、文字列の長さをカウントしたりする処理がとても簡単になるなどのメリットがあります。
その場合には、UTF-32 というエンコーディングを使うとよいでしょう。
UTF-32 という変換規則にのっとると、先ほどの 'Hello' は
00000048 00000065 0000006C 0000006C 0000006F
というバイナリデータに変換されます。(各コードポイントを 32 bit で表現)
ちょっと贅沢な記憶領域の使い方に思えますが、記憶領域の経済性よりもデータとしての扱いやすさを重視する場合は有効な方法でしょう。
これにもリトルエンディアンとビッグエンディアンがあり、UTF-32 LE とか UTF-32 BE とか表記します。
BOM を入れたら LE や BE は付けず、単に UTF-32 と呼ぶのは UTF-16 と同様です。
UTF-32 の表現できる範囲は UTF-8 と同様、UCS4 という文字集合のすべてです。
その他のエンコーディング
実は、おなじみの Shift-JIS や EUC-JP も符号化方式の一種です。ただし、Shift-JIS や EUC-JP は Unicode よりも小さな文字集合にしか対応していない(Unicode 内のすべての文字をエンコーディングできるわけではない)と考えてください。(たとえば韓国語の文字やアラビア文字などが文字集合に含まれていない)
まとめ:
Unicode = 文字集合、UTF-8, UTF-16, UTF-32, ... はコードポイントを符号化する方式。
これだけ覚えておけば、Unicode が意外とすっきりしたものに思えてくるのではないでしょうか。
ていうか Joel on Software にはもっと面白おかしくわかりやすく書かれているのでぜひ読んでみてください。

当時のブログ記事に寄せられていた あまの 先輩のコメントも非常に参考になりますので合わせて掲載しておきます。
あと一点だけ、超初心者にも押さえておいて欲しい点があります。
それは正規化形式についてです。
「一文字に見える文字」(書記素クラスタといいます)が複数のコードポイントからなる場合があります。 そして同じ文字でも、複数通りの表現方法があり得ます。
たとえば「ば」は、U+3070 というコードポイント1つで表すこともできるし、U+306F U+3099 という2コードポイントで表現も可能です。
複数通りの表現方法のうち、どれを採用するかのルールが正規化形式です。
それがわからないと Win32 API の ::MultibyteToWideChar() の dwFlag で言うなら、MB_PRECOMPOSED と MB_COMPOSITE の使い分けが理解出来ないので。。。(前者が NFC、後者がNFDと呼ばれている正規化形式です)
つまり、「どの正規化形式を使い」、そして「どのエンコーディング方式でエンコードしているか」の両方を意識するようにして下さい。
以上です。
soracom-cli のちょっと便利な Tips
この記事は 株式会社ソラコム Advent Calendar 2021 の 12/4 の記事です。
こんにちは。私はソラコムで soracom-cli を開発しています。soracom-cli は、IoT プラットフォーム SORACOM が提供している API をコマンドラインやシェルスクリプトなどから簡単に呼び出せるコマンドです。
例えば、持っている SIM の一覧を取得するには
soracom sims list
というコマンドを実行するだけです。
結果は JSON で返ってくるので、jq コマンドなどでさらに処理をつなげることができて便利です。
インストール方法はとっても簡単で、README に書いてありますが、Mac や Linux であれば
brew tap soracom/soracom-cli brew install soracom-cli
これだけでインストールできます。
ではここからは、すでに soracom-cli をお使いいただいている皆様のために、あまり知られていないけど知っているといざというときちょっと便利な Tips を 2 つご紹介したいと思います。
「API Key や API Token が欲しい・・・」
何らかの理由で唐突に API Key や API Token が欲しくなることって、よくありますよね。
たとえば API リファレンスでちょっと API を試してみたくなったときとか(通常はそのページから認証を行って API Key や API Token を取得しますが、実はこのページに API Key / API Token / Operator ID を直接手で入力することも可能なのです!)、soracom-cli でたくさんのコマンドを実行したいときに実行時間を短縮させるために認証を一度だけ行って API Key と API Token を使いまわしたい時とか、あるいは API Token の JWT を無性に解読してみたくなったときとか、自分の API Key の UUID を占いに使いたくなったときとか、自分の Operator ID で語呂合わせを考えたくなったりしたような場合です。(まともな用途が一つしかありませんね・・・さてどれでしょう!?)
そんなときには soracom auth コマンドを実行していただくことでいつでも簡単に API Key や API Token が欲しいという欲求を満たしていただくことができます。
soracom auth --email <email> --password <password>
しかし、メールアドレスはまだしもパスワードを直接書くのはなんか嫌ですね。シェルから実行するとしても画面を後ろから覗き込んでる人がいないかとか心配になりますし、実行した後もヒストリに残ったりしてしまいます。ましてやスクリプトの中になんか絶対に書いてはいけませんね。
そもそも意識の高い皆様はパスワード認証ではなく認証キーによる認証を行われていることでしょうから、keyId-NIWXcjCh..... とか secret-pJHehi5i..... みたいな記号の羅列を記憶しておいて入力するなんてことは現実的ではありませんし、これもスクリプトに書いておいてはいけない秘密の情報です。
ではどうすればよいのか?
みなさん、soracom-cli を使い始める一番最初に soracom configure を実行されたかと思います。
そのときに、パスワードとか認証キーを入力しましたよね? それは安全な形で(自分自身しか読み書きできない権限で)コンピュータのストレージに保存されています。
これを使えばいいのです!
では soracom configure したときに入力したそれらパスワードや認証キー(いわゆるクレデンシャル)はどこに保存されているのでしょうか?
答えは $HOME/.soracom/ ディレクトリです。(Mac や Linux の場合。Windows の場合は %HOME%\.soracom\ もしくは %USERPROFILE%\.soracom\)
soracom configure に --profile 引数を指定せずに実行した場合はそのディレクトリに default.json という名前で保存されています。
試しに cat $HOME/.soracom/default.json を実行してみてください。
パスワードもしくは認証キー情報が見えましたか?
ではこれを使うにはどうしたら良いでしょう? JSON ファイルなので jq コマンドで取り出す?
email="$( cat $HOME/.soracom/default.json | jq -r .email )" password="$( cat $HOME/.soracom/default.json | jq -r .password )" soracom auth --email "$email" --password "$password"
いえいえ、実はもっと簡単な方法があるのです。以下のようにして、soracom auth コマンドに直接そのファイルを渡してしまえばよいのです。
soracom auth --body @"$HOME/.soracom/default.json"
SORACOM の API は HTTP によるいわゆる REST API ですので、--body 引数は、API を呼び出すときのリクエストの Body の内容を指定するための引数です。
--body 引数の最初の文字を @ にすることで、それ以後の文字列はファイル名の指定とみなされます。その指定されたファイルの中身を読み込んでそのまま body として渡すという動作になります。
そして $HOME/.soracom/default.json に保存されている JSON ファイルの形式は、実は Auth API のリクエストボディと互換性のあるフォーマットになっているのです!なのでこのファイルを直接引数に渡すことが可能となっているのです。
もし複数の profile を使いこなされている場合は、引数の JSON ファイルを使い分けることで、それぞれの profile のための API Key や API Token を簡単に入手できます。
cred1="$( soracom auth --body @"$HOME/.soracom/profile1.json" )" cred2="$( soracom auth --body @"$HOME/.soracom/profile2.json" )"
soracom-cli が実際に送受信しているデータを盗み見たい
何らかの理由で唐突に soracom-cli がやり取りしている HTTP リクエスト・レスポンスの中身を見たくなることって、よくありますよね。
レスポンスは大抵の場合は soracom-cli が表示する JSON そのものですから、主に見たいと思うのはリクエストのヘッダーやボディ、それにレスポンスのヘッダーなどかと思います。
たとえば「自分が指定したパラメータは期待したとおりに送信されているのだろうか?」とか「この API を自分のプログラムから呼び出してみたいけど、パラメータの指定の仕方がよくわからないなぁ。soracom-cli はどうやって送っているのだろう?」といったような場合です。
そんなときはとても簡単です。
SORACOM_VERBOSE=1 soracom sims list
このように SORACOM_VERBOSE 環境変数に何らかの値を設定してあげればよいのです。
(上の例では 1 を指定していますが、今のところこの値に特に意味はありません。この環境変数が空でなければ verbose な出力が得られます。)
これを付けた状態で実行してみると、以下のような出力が得られると思います。(センシティブな情報は (snip) で置き換えてあります)
$ SORACOM_VERBOSE=1 soracom sims list
POST /v1/auth? HTTP/1.1
Host: api.soracom.io
Content-Type: application/json
User-Agent: soracom-cli/0.10.4
X-Soracom-Lang: en
{"email":"(snip)","password":"(snip)"}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Cache-Control: no-cache
Connection: keep-alive
Content-Type: application/json
Date: Wed, 01 Dec 2021 06:46:59 GMT
X-Soracom-Cli-Version: v0.10.4
==========
GET /v1/sims? HTTP/1.1
Host: api.soracom.io
User-Agent: soracom-cli/0.10.4
X-Soracom-Api-Key: (snip)
X-Soracom-Lang: en
X-Soracom-Token: (snip)
HTTP/1.1 200 OK
Cache-Control: no-cache
Connection: keep-alive
Content-Type: application/json
Date: Wed, 01 Dec 2021 06:46:59 GMT
Vary: Accept-Encoding
X-Soracom-Cli-Version: v0.10.4
==========
[
{
"activeProfileId": "(snip)",
"capabilities": {
"data": true,
"sms": false
},
"createdTime": 1445512349601,
"expiryAction": null,
"expiryTime": null,
"groupId": null,
...
これを見ると、以下のようなことがわかります。
- まず最初に
/v1/authAPI が呼び出されていて認証処理が行われています。認証結果は表示されていませんが、実際にはレスポンスとして返って来ています。 - 次に
/v1/simsAPI が呼び出されていてその結果が表示されています。/v1/authAPI の結果で得られた API Key や API Token がリクエストのヘッダに指定されています。
次に、以下のような引数を渡すようなコマンドを実行してみましょう。どのように API が呼ばれるかがわかります。
$ SORACOM_VERBOSE=1 soracom sims update-speed-class --sim-id 89xxxxxxxxxxxxxxxxx --speed-class s1.4xfast
POST /v1/auth? HTTP/1.1
Host: api.soracom.io
Content-Type: application/json
User-Agent: soracom-cli/0.10.4
X-Soracom-Lang: en
{"email":"(snip)","password":"(snip)"}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Cache-Control: no-cache
Connection: keep-alive
Content-Type: application/json
Date: Wed, 01 Dec 2021 07:10:42 GMT
X-Soracom-Cli-Version: v0.10.4
==========
POST /v1/sims/89xxxxxxxxxxxxxxxxx/update_speed_class? HTTP/1.1
Host: api.soracom.io
Content-Type: application/json
User-Agent: soracom-cli/0.10.4
X-Soracom-Api-Key: (snip)
X-Soracom-Lang: en
X-Soracom-Token: (snip)
{"speedClass":"s1.4xfast"}
HTTP/1.1 200 OK
Cache-Control: no-cache
Connection: keep-alive
Content-Type: application/json
Date: Wed, 01 Dec 2021 07:10:42 GMT
Vary: Accept-Encoding
X-Soracom-Cli-Version: v0.10.4
==========
{
"activeProfileId": "(snip)",
"capabilities": {
"data": true,
"sms": false
},
"createdTime": 1590234187495,
"expiryAction": null,
"expiryTime": null,
...
"speedClass": "s1.4xfast",
...
--sim-id で指定した SIM ID は POST 時の path の一部として、--speed-class で指定した速度クラスは body の JSON の中に入ってリクエストとして送られていることがわかりますね。
なお、SORACOM_VERBOSE を指定することで表示されるようになった部分は標準エラー出力 (stderr) に出力されており、API のレスポンスは従来どおり標準出力 (stdout) に出力されていますので、標準エラー出力の方は人間が目で確認しつつ標準出力の方はパイプなどで他のプログラムに渡して処理を行うといったようなこともできるようになっています。(既存のスクリプトのデバッグのときなどに役立つかもしれません)
また、レスポンスのヘッダに X-Soracom-Cli-Version が含まれていることにお気づきでしょうか?
このヘッダには現在リリースされている最新版の soracom-cli のバージョンが含まれています。
SORACOM API 側は、リクエストの User-Agent を見て soracom-cli からのリクエストのようであると判断した場合このヘッダを返します。
soracom-cli 側はこのヘッダを受け取ったら、自分自身のバージョンと比較して、新しいバージョンがリリースされている場合に以下のようにお知らせしてくれます。
$ soracom subscribers list
The latest version v0.10.4 is released which is newer than current version v0.10.3. Please update to the latest version.
[
{
"apn": "soracom.io",
"createdAt": 1463402658584,
"createdTime": 1463402658584,
"expiredAt": null,
"expiryAction": "doNothing",
"expiryTime": null,
...
日本語環境ですと、以下のように日本語のメッセージになります。
現在お使いのバージョン v0.10.3 より新しい v0.10.4 がリリースされています。アップデートしてください。
このメッセージも標準エラー出力に出力されますので、標準出力を利用している既存のスクリプトを壊してしまうことがないようになっているはずです。
さいごに
いかがでしたでしょうか。今後のみなさまの soracom-cli ライフが捗りそうな情報は一つでもありましたか?
soracom-cli はオープンソースとして開発されていますので、フィードバック、リクエスト、いつでも(クリスマスの時期に限らず) お寄せください。
サポートが終了した Runtime を使っている AWS Lambda の関数を見つけるスクリプト
前回の記事にも書きましたが、先月末(2021年4月末)ころに AWS から AWS Lambda の Node.js 10.x Runtime のサポートが終了しますというお知らせが来ていました。
それで仕事や個人で使っている AWS アカウントの Lambda 関数の Runtime をちょっと見てみたところ、Node.js 10.x どころか nodejs8.10 だの nodejs6.10 だの、しまいには無印の nodejs(Node.js のバージョンは 0.10 らしいです)なんかも見つかり、これはいかんということで全アカウントの全リージョンの全 Lambda 関数を棚卸ししてみることにしました。
しかし仕事のアカウントでは Lambda 関数の数は(Runtime のバージョンが問題ないものも合わせて)1,000 をはるかに超えていて、各関数にも複数のバージョンがあります。アカウントもいろいろな用途等に応じて複数の本番環境があったり開発環境があったりなどして複数にまたがっていますし、それら複数のアカウントでそれぞれ複数のリージョンを利用していたりします。
そんなわけで、手作業で調べるのでは時間がいくらあっても足りなさそうです。
AWS からのお知らせに書かれていた、aws lambda list-functions コマンドの例をベースにして改良を加えていった結果、以下のようなスクリプトが出来上がりました。
#!/usr/bin/env bash
set -Eeuo pipefail
profiles=(production staging development) # replace this with your aws account profiles
outdated_runtimes="$( curl -s https://docs.aws.amazon.com/lambda/latest/dg/runtime-support-policy.html 2>&1 | sed -n 's|.*<code class="code">\([^<]*\)</code>.*|\1|gp')"
select_outdated_runtime="$( echo "$outdated_runtimes" | sed 's/^\(.*\)$/"\1"/' | sed 's/^/.Runtime == /g' | sed ':a; N; $!ba; s/\n/ or /g' )"
for profile in "${profiles[@]}"; do
regions="$( aws ec2 describe-regions --query "Regions[*].[RegionName]" --output text --profile "$profile" --region ap-northeast-1 )"
for region in $regions; do
>&2 echo -e "\\033[1;31m$profile - $region\\033[0m"
functions="$( aws lambda list-functions --function-version ALL --profile "$profile" --region "$region" | jq -r '.Functions[] | select('"$select_outdated_runtime"') | [.Runtime, .FunctionName] | @csv' | sort | uniq )"
for fn in $functions; do
echo "$profile,$region,$fn"
done
done
done
実行には aws jq curl などのコマンドが必要です。
手元の Ubuntu 20.04 では動作していますが、mac だと sed のあたりの挙動の違いが原因で期待通りに動かない可能性があります。
このスクリプトをお使いになる際には 4 行目の profiles のカッコの中をご自身のご利用になっている AWS アカウントのプロファイル名(aws configure --profile <profile> で指定したプロファイル名)に置き換えてください。
「プロファイルってなんのこと?」という方はおそらく profiles=(default) とかすると良いかと思います。
このスクリプトを実行すると、以下のような感じでプロファイル名、リージョン名、ランタイム名、関数名を CSV 形式で出力してくれます。(進捗状況を示すために stderr に表示している プロファイル名 - リージョン名 は省略)
production,ap-northeast-1,nodejs10.x,hoge-fuga-func production,ap-northeast-1,nodejs8.10,foo-bar-func production,us-west-2,python2.7,test development,ap-northeast-1,nodejs,hello-world
.csv な拡張子を持つファイルに結果をリダイレクトして保存すると、それを Excel などで開いて閲覧・編集ができます。
解説
半年後の自分のために備忘録的に一応解説を書き残しておきます。
1〜2 行目はボイラープレートというか、bash スクリプトを書くときのお決まりの書き出し部分ですね。 詳しいことは以下の記事を参考にするとよいのではないでしょうか。
4 行目の profiles= の行は先ほど書いたとおり AWS アカウントのプロファイル名を配列として列挙します。ここに書いた各プロファイルに対して Lambda 関数をチェックしていきます。
6 行目では、AWS の以下のサイトをスクレイピングして、サポートが終了した(もしくは近いうちに終了する)ランタイムの一覧を取得しています。(もっと良い方法があったらお知らせください)
なおこの方法は同僚の Jed が教えてくれました。jed++
もし上記サイトの URL や内容が変化してうまくスクレイピングできなくなったら
outdated_runtimes="python2.7
ruby2.5
:
(省略)
:
dotnetcore1.0"
のように手で直接書くようにしてみてください。
6 行目で取得したランタイムの一覧は以下のような感じになります。
python2.7 ruby2.5 nodejs10.x nodejs8.10 nodejs6.10 nodejs4.3-edge nodejs4.3 nodejs dotnetcore2.0 dotnetcore1.0
これを 7 行目で加工して、以下のような文字列に変換しています。
.Runtime == "python2.7" or .Runtime == "ruby2.5" or .Runtime == "nodejs10.x" or .Runtime == "nodejs8.10" or .Runtime == "nodejs6.10" or .Runtime == "nodejs4.3-edge" or .Runtime == "nodejs4.3" or .Runtime == "nodejs" or .Runtime == "dotnetcore2.0" or .Runtime == "dotnetcore1.0"
これはあとで jq の select で対象の Runtime を見つけるのに使っています。
9 行目から各プロファイルに対してループを開始します。
10 行目では、そのプロファイルで利用可能なリージョンの一覧を取得します。
11 行目から各リージョンに対するループを開始します。
12 行目は進捗状況を stderr(標準エラー出力)に出力しています。
13 行目は aws コマンドで関数の一覧を取得し、jq でサポート切れの Runtime のみを抽出して、その Runtime と関数名を CSV 形式で出力しています。aws lambda list-functions に --function-version ALL を指定しているので、同じ関数の過去のバージョンもすべてチェックしますが、そのせいでバージョンが違うだけの同じ名前の関数が複数出力されます。それを | sort | uniq で重複排除しています。
14〜16 行目では、関数の一覧にプロファイル名とリージョン名も付けて CSV 形式で出力しています。
余談
私は以前 Go で Lambda のコードを書くために apex を利用していました。現在は Go の Runtime が AWS から公式に提供されていますが、数年前は Go の Runtime が無かったので Node.js を Runtime として用いて Node.js のコードから Go のプログラムを起動するというような方法で実行していました。apex はそのあたりをうまいこと隠蔽してくれていたので使っていたという背景があります。
Go のRuntime が正式にサポートされるようになってからは apex も Go の Runtime を直接使ってくれるようになりましたが、過去に Node.js ランタイムを使ってアップロードされたバージョンはそのまま残っていました。
今回検出された古い Node.js ランタイムの大部分はそのような経緯で作られたもので、すでに使われていない(Go Runtime に移行済みの)関数のバージョンばかりでした。
なお今は apex の開発が停止してしまったのでいろいろな代替ツールを試しましたが、私は個人的には AWS CDK に落ち着いています。
AWS CDK で Lambda 関数を作ったときに Log の Retention Period を指定したらちょっと面白かった話
先日、AWS CDK を使ってとある Lambda 関数をデプロイしました。 その Lambda 関数は Go で書かれたものですが、動作に必要な S3 や DynamoDB などのリソースを準備したり IAM Role に適切な Policy を設定してそれを使うようにしたり Lambda 関数自体のメモリサイズやタイムアウト時間などいろいろなパラメータを指定しなければなりません。しかもこの関数を開発用の AWS アカウントと本番環境用の AWS アカウント両方に作らなければなりません。このような場合には CDK のような IaC (Infrastructure as Code) の実現を支援してくれる仕組みはありがたいですね。
で、今回構築した Lambda の関数名を仮に FooFunc とでもしておきましょう。
CDK のコードは TypeScript で書きました。 lambda.Function コンストラクトを用いて以下のように構築しました。
const fn = new lambda.Function(this, 'FooFunc', {
functionName: 'FooFunc',
runtime: lambda.Runtime.GO_1_X,
handler: 'foo',
code: lambda.Code.fromAsset('./foo.zip'),
role: role,
memorySize: 1024,
timeout: cdk.Duration.seconds(30),
logRetention: cwlogs.RetentionDays.ONE_WEEK,
currentVersionOptions: {
removalPolicy: cdk.RemovalPolicy.RETAIN,
},
});
これでデプロイすると FooFunc が出来上がっていて期待通りに動きました。
Lambda のログの保持期間 (logRetention) を 1 週間に指定してあります。 これを忘れると CloudWatch Logs に永遠にログが残り続けて地味に費用がかさんでしまうので、この設定をしっかりと行っておくのがよいですね。
で、この連休中に AWS からお知らせが来て、Node.js 10.x の Runtime はサポート終了ですよ、とのこと。4/30 に Node.js の本家が 10.x のサポートを終了したのに合わせ、AWS も 7 月末でサポートを終了するのでそれまでにより新しいバージョンに移行するように、とのことでした。
お知らせにはご丁寧に aws cli で Node.js 10.x の Runtime を使っている Lambda 関数の一覧を出力するためのコマンドラインまで書かれていましたのでそれを実行してみました。
すると、先日作ったばかりの FooFunc の名前が見つかったのです。
FooFunc の Runtime は Go のはずなのにおかしいな、と思いました。
Node.js 10.x を使っているとして見つかった関数の名前は、正確には FooFunc_LogRetention${UniqueID} のような長い名前でした。${UniqueID} の部分はランダムな英数字の 30 文字くらいの羅列です。長いので LogRetention 関数と呼ぶことにします。
自分ではそのような関数を作った覚えはありませんが、CloudFormation の Stack を見るとたしかに FooFunc の仲間です。
名前からすると Log の Retention Period を設定するための関数のようです。 コードを読んでみてもやはりそのような処理の内容が書かれていました。
で、この LogRetention 関数の Runtime が Node.js 10.x だったわけです。
僕が使っていた CDK のバージョンがちょっと古かったためでしょうか。すぐに CDK のバージョンを更新しました。
LogRetention 関数の Runtime のバージョンを試しに手動で最新の 14.x に上げてみて、その後に CDK で FooFunc をデプロイしてみましたが、Node の Runtime バージョンが巻き戻ったりすることもなく、logRetention の設定もきちんと反映されましたのでとりあえずはこの状態で運用していこうと思います。
Rust で書いたコードを AWS Lambda で動かす
Mac でクロスコンパイルしたバイナリを Lambda で動かすという記事はあったのですが、Linux でビルドして Lambda で動かすという記事が見当たらなかったのと、それなりに躓いたのでメモを残しておきます。
Rust 自体はインストールできてるとして、大まかな手順としては、
rustupで targetx86_64-linux-unknown-muslを追加する- musl-gcc をインストールする
cargoでビルド- Lambda にデプロイ
ではそれぞれ詳細な手順をば。
1. rustup で target x86_64-linux-unknown-musl を追加する
これは以下のコマンドを実行するだけですね。
rustup target add x86_64-linux-unknown-musl
2. musl-gcc をインストールする
Mac だと brew で、Ubuntu だと apt で入れられるっぽいのですが、私の使っている Amazon Linux だと yum で入れる方法がわからなかったのでソースからビルドしました。
GitHub - richfelker/musl-cross-make: Simple makefile-based build for musl cross compiler
こちらのリポジトリをクローンしてきて、
TARGET=x86_64-linux-musl make
これにはしばらく時間がかかります。
ビルドが完了したら
make install
これで output ディレクトリ以下に成果物ができます。
成果物を適当なディレクトリにコピーします。
sudo cp -f output/* /usr
cargo でビルド
AWS Lambda で動く Rust のコードは AWS のオフィシャルなブログでサンプルコードが公開 されています。
まずはこちらのコマンドを実行して雛形を作っていきます。
cargo new my_lambda_function --bin
記事に書かれているように Cargo.toml の [dependencies] セクションの内容を追加していきます。
[package] セクションに autobins = false を追加するのを忘れずに。
[[bin]] セクションも追加します。
.cargo ディレクトリを作成し、その下に config というファイルを作って以下のような内容を書きます
[target.x86_64-unknown-linux-musl] linker = "x86_64-linux-musl-gcc"
そしてこれをビルドします。
CC_x86_64_unknown_linux_musl="x86_64-linux-musl-gcc" cargo build --release --target x86_64-unknown-linux-musl
ビルドが成功すると、以下の場所にファイルができています。
$ file target/x86_64-unknown-linux-musl/release/bootstrap target/x86_64-unknown-linux-musl/release/bootstrap: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped
static link されていますね。
これを zip します。
zip -j rust.zip ./target/x86_64-unknown-linux-musl/release/bootstrap
4. Lambda にデプロイ
AWS の管理コンソールにログインして Lambda の関数を新しく作ります。
Auth from scratch を選択して Runtime は Provide your own bootstrap を選択します。
Function code で Upload a .zip file を選択して先程作成した rust.zip をアップロードします。
Save を押します。
以下のようなテストデータを作成してテストを実行してみましょう。
{
"firstName": "Takashi"
}
実行が成功して以下のようなレスポンスが得られたら成功です!
{
"message": "Hello, Takashi!"
}
Go 製 WebAssembly ホスト環境パッケージ wax のご紹介
みなさんこんにちは。
これは Go2 Advent Calendar 2019 の 12 月 24 日のための記事です。(少しフライング気味に投稿しておきます)
今日は個人的な趣味で作っている wax というライブラリのご紹介をしたいと思います。
3 行で
- WebAssembly のホスト環境(実行環境、ランタイムともいう)を Go で書いてみました。
- なので、WebAssembly だけど Web ブラウザは出てきません。フィボナッチ数の計算とかはできます。
- エミュレータを作ってるみたいで楽しいけど、一人で開発するのは辛いので仲間募集中です!
WebAssembly のホスト環境って?
WebAssembly というと、Go や Rust などの言語で書いたプログラムを Web ブラウザの上で実行させることができるということを思い浮かべられる方が多いと思います。それは WebAssembly の本来の目的というか、典型的な使い方だと思います。私はそういうメジャー路線にはいつも乗りそこねてしまうタイプであり、このところの WebAssembly のブームに関しても私はそこまで興味を持っていなかったというのが本当のところでした(「asm.js がバイナリになったんでしょー」(←多分違うw)とか「ブラウザで 3D ゴリゴリなゲームとかプレイしたい/作りたい人のためのものでしょー」くらいの認識でした)。
ところがある日、何かの拍子に WebAssembly の仕様書を拾ってしまったのです。
https://webassembly.github.io/spec/core/_download/WebAssembly.pdf
ちょっと目次などを眺めてみたらこれがまた面白そう。何が面白そうかって .wasm ファイルのバイナリフォーマットが定義されているんです。
バイナリを見るとパースせずにはいられない私としては、実物の .wasm ファイルをパースしてみたくなりました。そんなわけでいろいろな言語で簡単なプログラムを wasm に出力してみて、仕様書とにらめっこしながらバイナリをパースするコードを書き、.wasm ファイルの内容を JSON でダンプするツールなんか書いているうちに、仕様書に命令セットの定義とかが出てきてワクワクしてきてしまい、コードの実行もしたい欲が高まって、気づいたら wax という名前まで考えていました。
wax の wa は WebAssembly、x は execution から取っています。
ググラビリティの低さは懸念ですが、後悔はしていません。
少し話がそれましたが、WebAssembly とはスタックベースの仮想マシンの命令セットとその実行環境・実行方法(セマンティクス)などを定めた仕様ですが、そのバイナリフォーマットは比較的軽量(命令コードは1バイト固定、オペランドはたとえば整数リテラルが可変長なので、小さな整数は 1 バイトで表せるなど)であり、セキュリティを意識した仕様 -- たとえば明示的にスタックを操作する命令がなかったりスタックのメモリ空間がプログラムからさわれる領域にはなかったり(というかそもそもスタックにはメモリのアドレスなどの概念がない)などスタックオーバーフローを利用した攻撃が難しそうなどなど -- になっていたりと、まさに Web のために作られたものである印象を受けました。
で、Web ブラウザ上で実行することはもちろん WebAssembly の主目的だと思うのですが、WebAssembly の仕様書の冒頭には以下のような文章もありました。
1.1 Introduction
WebAssembly (abbreviated Wasm) is a safe, portable, low-level code format designed for efficient execution and compact representation. Its main goal is to enable high performance applications on the Web, but it does not make any Web-specific assumptions or provide Web-specific features, so it can be employed in other environments as well.
訳すると、
「1.1 イントロダクション
WebAssembly(Wasm と省略される)は安全、ポータブル、低レベルのコードフォーマットであり、効率的な実行とコンパクトな表現のためにデザインされた。そのメインのゴールは Web 上でハイパフォーマンスなアプリケーションを可能にすることだが、いかなる Web 固有の仮定をすることもなく Web 固有の機能を提供することもない。そのため他の環境でも同様に用いることができる。」
仕様書の冒頭のこの部分を読んだ時点で、私の WebAssembly に関するそれまでの狭い理解はぶち壊されました。
WebAssembly を自分のプログラムでホストする、すなわち WebAssembly の実行環境を自分のプログラムに組み込むことで、自分のプログラムでプラグインのような任意のサブプログラムを実行できるようになるということだと理解したのです。
たとえば Wireshark では独自の Dissector を Lua で書いて組み込むことができますが、Lua という言語を知らない人には敷居が高くなってしまいます。(Lua はシンプルな言語なので簡単に使えるようになるとは思いますが、それをメンテナンスしたりすることを考えると、たとえばチーム内でよく使われている言語を使いたくなったりすると思います。)
また、もし自分のプログラムのプラグイン機能を提供するとした場合、ユーザーにある特定の言語を利用することを強要するような感じになってしまうのは気が引けるというか、できればユーザーが自分の好きな言語でプラグインを書くことができるととてもよいと思いませんか?
それ(ユーザーが好きな言語でプラグインを書けること)を可能にするのが WebAssembly のもたらすもののうちの一つだと考えています。
WebAssembly の実行環境をホストすることで、自分のプログラムにユーザーのコードを安全に組み込むことができ、かつユーザーは自由な言語を利用できるようになる。
これまでその2つ(安全性の確保と自由な言語の利用)を両立させようとするとおそらく実質的には何らかのコンテナ技術を使うしかなかったと思うのですが、WebAssembly の登場によってより軽量に、さまざまな環境でそれを実現することができるようになると思います。
Fun fact: Webassembly is neither web nor assembly. It can be run out side browser too. Its called WASI, web assembly system interface. Its so crazy and at the same time so powerful, Solomon Hykes said, If WASM+WASI existed in 2008, we wouldn't have needed to created Docker🤯
— sreenivas (@CgCnu) December 12, 2019
拙訳:
面白い事実:WebAssembly は Web でもなければアセンブリでもない。ブラウザの外でも実行できる。それは WASI (WebAssembly System Interface) と呼ばれる。とてもクレイジーであると同時にとてもパワフルである。Solomon Hykes (訳注:Docker の創業者兼 CTO)が言っていた:もし 2008 年に WASM と WASI が存在していたら、我々は Docker を作る必要はなかったかも🤯
実際、Envoy Proxy では WebAssembly で書かれた Extension をサポートするというニュース がつい最近ありました。
また CDN の Fastly は CDN の Edge でユーザーの任意のコードを実行できる仕組みとして WebAssembly を実験的に採用しました。(そのエンジンの Lucet は最近 Bytecode Alliance(WebAssembly の規格化団体)に移管されたようです)
今後、そのように、ユーザーのコードを実行することでプラットフォームやソフトウェアの機能拡張をするような場面では WebAssembly の採用がどんどん進んでいくのではないかと思います。
どうやって WebAssembly をホストするの?
wax のパッケージ(Go 言語の意味でのパッケージ)は WebAssembly ホスト環境のライブラリですが、そのパッケージを利用したその名も wax というコマンドも用意しています。
wax コマンドは .wasm ファイル(の中の指定された関数)を実行して結果を表示するプログラムですが、これは wax パッケージの具体的な利用例にもなっています。
基本的には wax.ParseBinaryModule() で .wasm ファイルをパースし、wax.NewRuntime() でランタイムを生成、runtime の FindFuncAddr() で関数を見つけ、同じく runtime の InvokeFunc() でその関数を実行するだけです。
InvokeFunc() の戻り値には、実行された wasm の関数の戻り値が含まれています。
なので、ホスト環境が Go 言語で書かれたプログラムであれば、wax を使うことで簡単に WebAssembly をホストすることができます。
現時点でできること・できないこと
できること:
- 算術演算(整数型・浮動小数点数型)- 単項演算、二項演算、比較、変換、など
- 関数呼び出し
- 分岐(条件分岐、ジャンプ、ループなど)
できないこと:
- ホスト環境の関数などのインポート
- WASI などの ABI のサポート
- 配列や文字列など、プリミティブ型(整数型、浮動小数点数型)以外を引数や戻り値に取る関数の実行 → これはそもそも仕様上無理かもしれません。ホスト環境のメモリ領域を Import してそれを介してやり取りする感じになるのが正解なのかも。というかその方法を定めてるのが WASI とかだと思うのでもっと勉強します
などなど
感覚的には、標準で用意されているテスト の正常系のうち、だいたい 7〜8 割くらいは通ってるかな、という感じです。
なので、まだまだできないことだらけではありますしおそらくバグとかも多いのですが、仕様書と格闘しながら少しずつできることを増やしていってる段階です。
プログラムを wasm 向けにコンパイルして実行してみよう
最近は いろいろな言語が wasm の出力をサポート しています。 今回は、その中から Go と Rust で書いたプログラムを wasm にコンパイルし、それを wax を使って実行してみたいと思います。
Go
みなさんの大好きな Go はもちろん wasm を出力できます。 しかし普通にやると GC や goroutine を含めた Runtime 全体が wasm になってしまい、出力されるバイナリのサイズが全然小さくなく wax で動かせる自身が全くないので、というかそもそも Go が吐き出す wasm のバイナリは JS 環境(ブラウザ)で使われることを前提としたものしか出力できなさそうなので wax ではきっと動かないので、今回の例では TinyGo を使って小さなバイナリを吐き出してみたいと思います。
TinyGo は Go のサブセットに対応したコンパイラで、組み込み向けの軽量なバイナリを出力します。
以下のようなコードを書いて、add.go というファイル名で保存してください。
package main func main() { } //go:export add func add(a, b int) int { return a + b }
main 関数が空ですが気にしないでください。
普通の Go には無い //go:export という指定があります。
これはこの関数を add という名前で export するという指定です。
ではこのソースを TinyGo でビルドします。今回は Docker で tinygo のコンテナの tinygo コマンドを使います。 add.go をおいたディレクトリで、以下のコマンドを実行します。
docker run --rm -v "$(pwd)":/src tinygo/tinygo:latest tinygo build -target wasm -o /src/add.wasm /src/add.go
これで add.wasm というファイルができるはずですので、次はこれを wax を使って実行します。
go install github.com/bearmini/wax/cmd/wax wax -f "add" -a "i32:1" -a "i32:2" add.wasm
go instal ~~ で wax コマンドをインストールしています。したがってこれは一度だけ実行すればよく、それ以降は wax コマンドを使えるようになります。($GOPATH/bin に PATH を通しておく必要があります)
wax コマンドの引数は -f で実行する関数の名前を指定しています。 -a は引数の指定です。型(i32)と値( 1 や 2)をコロン : でつなげて指定します。負の数や 16 進数でも指定できます。
最後に .wasm ファイル名を指定しています。
これを実行し、結果として以下のように表示されれば成功です!
0:i32:0x00000003 3 3
これは、関数の 0 番目の戻り値1 が i32 型で、0x00000003 という値だったことを示します。
その後の 2 つの 3 は、0x00000003 を 10 進数で表したもので、符号なしと符号付きでの解釈をそれぞれ示しています。
wax リポジトリには、.wasm ファイルを実行する wax コマンドの他に、.wasm ファイルの内容を JSON 形式で dump する wadump というツールや、.wasm ファイルに含まれるコードを逆アセンブルする wadisasm というツール、デバッグシンボルの情報などを削ぎ落として .wasm ファイルを軽量化 (strip) する wastrip というツールも含まれています。
これらも実行してみましょう。
まずは wadump から。
go install github.com/bearmini/wax/cmd/wadump wadump add.wasm
すると以下のような結果が表示されるはずです。
{"Preamble":{"MagicNumber":1836278016,"Version":1},"Sections":[{"ID":1,"Size":30,"Content":"BmAAAX9gA39/fwF/YAAAYAF/AGACf38AYAJ/fwF/","FuncTypes":[{"ParamTypes":"","ReturnTypes":"fw=="},{"ParamTypes":"f39/","ReturnTypes":"fw=="},{"ParamTypes":"","ReturnTypes":""},{"ParamTypes":"fw==","ReturnTypes":""},{"ParamTypes":"f38=","ReturnTypes":""},{"ParamTypes":"f38=","ReturnTypes":"fw=="}]},{"ID":2,"Size":42,"Content":"AgNlbnYNaW9fZ2V0X3N0ZG91dAAAA2Vudg5yZXNvdXJjZV93cml0ZQAB","Imports":[{"Mod":"env","Nm":"io_get_stdout","DescType":0,"Desc":0},{"Mod":"env","Nm":"resource_write","DescType":0,"Desc":1}]},{"ID":3,"Size":17,"Content":"EAICAgICAgECAgMEAgUFBQU=","Types":[2,2,2,2,2,2,1,2,2,3,4,2,5,5,5,5]},
...(省略)
続いて wadisasm
go install github.com/bearmini/wax/cmd/wadisasm wadisasm add.wasm
以下のような逆アセンブル結果が表示されます
func:0 0b end func:1 10 84 80 80 80 00 call funcidx:00000004 0b end func:2 3f 00 memory.size 0x00 41 10 i32.const 00000010 74 i32.shl 41 c6 80 84 80 00 i32.const 00010046 ...(省略)
アセンブルリストの中に以下のような関数を見つけることができるでしょうか。
func:12 20 01 local.get 00000001 20 00 local.get 00000000 6a i32.add 0b end
func のあとの番号は使った TinyGo のコンパイラのバージョンなどによって変わってくるかもしれませんが、命令列の中に i32.add とありますね。この命令はスタックに積まれた 2 つの 32bit 整数を取り出し、加算を行って結果をスタックに戻す命令です。そしてこの関数こそが Go のソースコードの add() 関数から生成されたWebAssembly のコードです。
wastrip も同様に実行してみてください。実行前と実行後で、ファイルサイズや wadump の結果を比べるとその差が一目瞭然でしょう。
他にも、リポジトリ の examples/go ディレクトリの下にはフィボナッチ数を計算するサンプルコードなどがありますので実行したり逆アセンブルしてみてください。
Rust
最近人気のある Rust も WebAssembly の出力をサポートしています。
以下のようなコードを書いて add.rs というファイル名で保存します。
#[no_mangle] pub extern fn add(a: u32, b: u32) -> u32 { a + b }
これをコンパイルします。
rustc --crate-type=cdylib --target wasm32-unknown-unknown -O add.rs
これで add.wasm というファイルができるはずです。
実行方法等は Go の方で説明したのと同じですので割愛します。
ほかにも Emscripten を使うと C/C++ から wasm を出力することができると思いますし、他の言語も wasm をサポートするものが増えていると思います。 皆様もいろいろな言語からコンパイルして生成した wasm を実行してみてください。
他のホスト環境との比較
私の知る限りでは、以下のようなホスト環境がすでに世の中に存在するようです。
これらの有名所の実行環境はだいたい LLVM などをバックエンドに使って wasm を JIT もしくは AOT してネイティブコードとして実行するものが多そうです。
wax は今の所 JIT に対応する予定はありません。パフォーマンス的には JIT する実装に比べて見劣りすると思いますが、Pure Go なことで組み込みやすいとか、何かしら wax らしい特徴を出していけたらいいな、と思っています。
それから、GitHub - appcypher/awesome-wasm-runtimes: A list of webassemby runtimes にはその他の実装もたくさん列挙されています。いつかここに wax も載ることができるとうれしいですね。
お仲間募集中
一人でコツコツ開発するのは気ままでいいのですが、仕様をどうやって解釈したらいいのかがわからなさすぎるときなどにモチベーションの維持が難しかったりするのでそういうときに相談できたりするお相手がいるとうれしいな、という気持ちです。 あと、MVP という最小限の仕様はまだ独力でもなんとかなりそうなのですが、スレッドや SIMD のサポートなど MVP 以上の実装をしようと思うとやはり一人では限界がありそうと今から感じています。
もし wax の開発に興味のある方は Twitter @bearmini にぜひお声がけいただければと思います。 Github 上での Issue や PR も大歓迎です~!
ということで、メリークリスマス!🎅
-
0 番目の戻り値、ということは1番目・2番め・・・の戻り値もあるのか、ということですが、現時点の WASM の MVP (Minimal Viable Product) では関数の戻り値は1つまで、ということになっています。将来のバージョンでは複数の戻り値を返す関数もサポートされる可能性があります。↩
SORACOM LTE-M Button powered by AWS(通称 #あのボタン)を使って EC2 のインスタンス代を節約した話
この記事は SORACOM Advent Calendar 2019 ふたつめ の 12 月 3日分です。
はじまり
最近、開発用の PC の調子が悪かったのもあって EC2 インスタンス上にいろいろな開発環境を構築してみています。 そうするとどの PC を使っても同じ開発環境で作業を継続できると思ったからです。
近頃は VS Code のリモート接続拡張を使うことで、あたかもローカルにファイルがあるかのようにリモートホスト上のファイルが編集でき、統合ターミナルを使って自然にリモートホスト上でコマンドを実行できますので、リモート接続していることを忘れてしまうときがあるほどなので、これさえあればだいぶ行けるだろうと思ったのです。
最初はお試しと思って t3.micro インスタンスで始めたものの、自分の書いたプログラムを Fuzzing したいと思ってぶっ通しでプログラムを実行しようとしたら CPU クレジット不足になってしまったので c5.large にインスタンスタイプを変更し、Fuzzing が終わって今度はいろいろテストを実行していたらメモリ不足になってしまったので r5.large に更に変更し、という感じで今に至っています。
ソラコムでは社員の福利厚生(?)として AWS のサービス使い放題というのがあるのですが、貧乏性の私はさすがに r5.large インスタンスを起動しっぱなしはもったいないなぁと感じてしまい、弊社の リーダーシップステートメント にも Avoid Muda とあるように少しでもコストを削減しようと思い、開発業務をしていない間はインスタンスをちゃんと停止しようと考えました。
r5.large インスタンスは Tokyo リージョンでは $0.152/hour (2019年12月現在)ですので、使っていない時間が1日の半分(12時間)あったとして1ヶ月(30日)で $0.152 * 12 * 30 = $54.72 のムダが生じていることになります。(実際には休日などもありますし、1日12時間も働くことはまれですし、もっとムダが生じてしまうことになるはずです。)
しかしながら生来のめんどくさがりである私は、インスタンスを起動したり停止したりするために AWS コンソールにログインして EC2 のページから自分のインスタンスを検索して起動したり停止したりするのは非常に面倒であると思いました。 aws コマンドを使ってコマンドラインで実行するともう少し手間は少ないかもしれませんが。
というわけで、ここはテクノロジーの力で解決しよう!(大げさ)と思って取り出したのがこちらの商品です。
そう、「AWS ボタン」とか「#あのボタン」と呼ばれているものです。
設計(というほどのものでもない、ただの思いつき)
目論見はこうです。
これだけです。 究極にシンプルです。
AWS ボタンは、1回押し(シングルクリック)、2回押し(ダブルクリック)、長押し(ロングクリック)の3タイプの押し方ができますので、これをそれぞれ以下のような機能に割り当てることにしました。
- シングルクリック:現在のインスタンスの状況(稼働中か、停止中かなど)を Slack のチャンネルに報告
- ダブルクリック:インスタンスが停止していたら起動。Slack のチャンネルに報告。
- ロングクリック:インスタンスが起動していたら停止。Slack のチャンネルに報告。
実装
ではここから実装に入っていきます。
AWS IoT 1-Click の設定
まずは AWS IoT 1-Click で AWS ボタンを Claim(登録)して有効化します。 手順などはこちらを参考にしてください。
Lambda で起動される関数を先に作成
今回は Go で Lambda 関数を作成しました。 Gist にコードを上げておきました。これをビルドして ZIP してアップロードします。
https://gist.github.com/bearmini/99e99ead08ed0e8aff39c6379f5aeeae
AWS IoT 1-Click に戻り、プロジェクトを作成
AWS IoT 1-Click で Project と Device template を作成します。

起動する Lambda は先程作ったものを指定します。
プレイスメントの設定
そのボタンで起動/停止したいインスタンスのインスタンス ID、リージョン、通知先の Slack の Incoming Webhook URL をプレイスメントで指定します。
実行!
ボタンを押してみます。
まずは恐る恐るシングルクリック。
ボタンの LED がオレンジ色に点滅して10秒ほど待つと緑色に光ります。 すると程なくして Slack に通知がくるはずです。

インスタンスを停止する際は長押しします。

インスタンスを起動する際はダブルクリックです。

インスタンスを停止すると、瞬間的に VS Code は画面が暗くなって再接続を試み始めます。
インスタンスを起動すると VS Code は再接続に成功します。画面を一度リロードする必要がありますが、それ以降は何事もなかったかのように作業を継続できます。(開いていたターミナルなどは閉じてしまいますが、screen コマンドなどでセッションを維持するようにすればそれも問題なく継続できるでしょう)
おわりに
というわけで、ちょっとの投資とちょっとの工夫、そしてちょっとの実装でこんなに簡単に節約ができました。
みなさんも、何かアイディアを思いついたら、Just Do It! してみましょう。