復刻版: 超初心者のための Unicode(ユニコード) 入門
優秀なエンジニアであっても、これまであまり直接関わってこなかった場合、案外文字コードのことについて詳しくは知らなかったりするものです。Unicode って何?UTF-8/16/32 の違いを説明できる?サロゲートペアって何?絵文字を UTF-8 で表現すると何バイトになる?そういった質問に自信を持って答えられるというエンジニアは実はそれほど多くなかったりするのではないでしょうか。
先日、Slack 上での同僚との会話の中から、
👨👩👧👦
という絵文字が UTF-8 で何バイトか?という話題になり、調べてみたところ 25 バイトという結論になりました。
確かめてみるには、
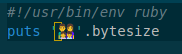
このようなコードを UTF-8 で emoji.rb というファイルに保存して、これを実行すると、
$ ruby emoji.rb 25
このような結果になります。
なぜそうなるのかを同僚には簡単に説明しましたが、Unicode とか UTF とか UCS といったような言葉の意味だったり、ほかにも様々な概念を正確に把握していないと、正しく理解することが難しいようでした。
ちなみに上記の絵文字は
- 男性の顔
- 女性の顔
- 女の子の顔
- 男の子の顔
の 4 つの絵文字を、Zero width joiner という特殊な符号で連結して一つの「家族(男性・女性・女の子・男の子)」という絵文字として扱っているという特殊なパターンです。
少し脇道にそれますと、「家族」を表す絵文字はこれだけではなく、両親が同性のパターンや片親のパターンも絵文字として存在しています。子どもも男の子 x 2 の場合や女の子 x 2 の場合、男の子か女の子が 1 人だけの場合も存在します。さらに特殊な符号を使うことで skin-tone(肌の色味)の指定も可能ですので、膨大な組み合わせを表現可能です。子どもの人数が 3 人以上の場合には今のところ対応していないようですが、1文字分のスペースにあまり詰め込みすぎても絵文字として見づらくなってしまうのでそこは仕方ないかなと思います。 いずれにせよ、それらの組み合わせ一つ一つにユニークなコードポイントを割り当ててしまうとキリがないので、基本となるパーツの組み合わせで絵文字が生成できるようになっているんですね。
そんな話をしたときに、ずっと昔に自分が書いた「超初心者のための Unicode(ユニコード)入門」というブログ記事のことを思い出しました。
当時(2006 年ころから 2010 年くらいまで)はブログシステムを自分で作っていて、レンタルサーバー(というか VPS)の上でホストしていたのでした。ブログ記事もブログシステムも更新しなくなってしまってドメイン名を expire させてしまったのと同時にそのシステムも撤収してしまったのでいまはその記事を読むことはできないのですが、今あの記事があったら同僚にも紹介できるし、もしかしたら今でもあの記事に少しは価値があって PV が稼げるかもしれないのになぁと思っていました。
そこで、ダメ元で Internet Archive で検索してみたところなんとその当時の記事が残っていました!
そんなわけでこの記事は当時の自分の書いた記事をサルベージして再掲するものです。
Internet Archive (Wayback Machine) には少しばかりですが寄付をしておきました。
では、復刻版の「超初心者のための Unicode(ユニコード)入門」、今となってはちょっと古くさく感じられる記述もあるかもしれませんが、そういうところまで含めてお楽しみください!
超初心者のための Unicode(ユニコード)入門
はじめに
XML ファイルの先頭(XML 宣言)にはとりあえず encoding="utf-8" って書いてみたり、C++ で Windows プログラムを書くときはなんとなく TCHAR とかを使ってみたり、「なんか Java とか C# とかは内部でユニコード使ってるらしいぞ」ということは知っていても実はそれがどういう意味なのかよくわかっていなかったり、「そろそろちゃんと Unicode を勉強しないといけないかな・・・でも、ネットで検索しても小難しい記事しか見つからなくてよくわかんないんだよな~」と思っていたりするそこのアナタ!
ていうか私自身が Joel on Software を読むまでその状態でした。Unicode のことをよく理解できていなかったというか、むしろ激しく誤解していました。
ただ、それは平易な日本語で書かれた Unicode 入門記事がネットに転がっていなかったからだと思います。(責任転嫁)
でも、大丈夫です。
Joel on Software にも書かれているとおり、
「Unicode はそんなに難しくない」
のです。
以下に示す、基本的な事実だけまずはおさえておけば、小難しい理屈やら歴史的事情やらは置いておいて、Unicode のことを理解できるはずです。
※ Unicode に詳しい方へのお願い
以下の文章は、厳密には間違いを含んでいるところがあるかもしれません。私自身、Unicode 初心者には変わりありませんので。もし、著しく事実と異なるような内容がありましたら遠慮なく指摘してください。
※ それから、Joel on Software を読んで Unicode に開眼したという筆者の個人的体験により、以下の文章の内容に 「Joel on Software のパクリじゃねーの?」 というものが含まれてしまうかもしれません。
著作権的に問題がありそうな点がありましたら、遠慮なく指摘してください。
それでは、超初心者のための Unicode 入門、始まり始まり~
Unicode = 文字集合
Unicode 入門といいつつ、ここでまず、Unicode のことはしばし忘れて、概念的なことを考えてみましょう。
仮に、あなたが出版社かどこかに勤めていたとして、上司から「今度わが社で "世界の文字字典(完全版)" を作ることになったので、世界中のありとあらゆる文字を全部集めて来なさい」と指示されたとします。
日本語と中国語で似てる漢字は同じ文字とするのか?とか、旧字は常用漢字と同じ文字とみなすのか?とか、全角数字の4と半角数字の 4 は同じ文字なのか違う文字なのか?とか、そういう難しいことはエライ人たちに任せるとして、あなたはとにかく文字という文字を世界中から手当たり次第に集め尽くしたとします。
そうやって集められた文字のことを、文字集合と呼びます。
そして、実はこの文字集合を作るという作業を公共的な機関で正式に行ったものが Unicode なのです。
Unicode は、文字をひたすら集めたもの=文字集合なのです。
ここで大事なのは、この時点では UTF- なんとかとか、サロゲートペアとか、意味不明な用語がまだ出てきていないということです。それらは、Unicode に含まれる文字をコンピュータ上でどう表現するかといった話なので、分けて考えましょう。
大前提として、「Unicode とはコンピュータ上の表現を離れた論理的な文字体系のことなのだ」と理解すると、それ以外の難しい話題も、もつれた糸がほどけるように徐々に理解できるようになっていくはずです。
コードポイント=文字の通し番号
文字を集めるだけ集めたら、その文字一つ一つにユニークな通し番号を付けたくなるというものです。(その理由としては、たとえば管理上便利だからとかいろいろあると思います)
Unicode でも文字に通し番号を割り当てていて、その通し番号のことをコードポイントと呼びます。
たとえば、アルファベットの 'A' は 65 番目(16進数で 0x41 番目) で、ひらがなの 'あ' は 12354 番目(16進数で 0x3042番目)です。
これらをそれぞれ U+0041 とか U+3042 と表記します。(U+ のあとに 16 進数 4 桁~ 6 桁くらいで表記します)
エンコーディング
ここでようやく、このコードポイントをどうやってコンピュータ上で扱うかという話になります。
たとえば、あなたが "こんにちは" という文字列を電子メールで送信したい場合、相手にどのようなバイナリデータを送信すればよいのでしょうか?
(メールのプロトコルとか難しいことはとりあえずひとまず置いといて。)
それぞれの文字のコードポイントは以下のように決められています。
| 文字 | コードポイント |
|---|---|
| こ | U+3053 |
| ん | U+3093 |
| に | U+306B |
| ち | U+3061 |
| は | U+306F |
(unicode.org の Unihan Database を参照しました)
各文字のコードポイントは、16 進数で 4 桁ずつなので、16bit で
3053 3093 306B 3061 306F
というデータを送ればよいような気がします。
リトルエンディアンな環境だと、バイトオーダーを入れ替えて
5330 9330 6B30 6130 6F30
というデータを送ったほうがよいかもしれません。
このように、コードポイントをコンピュータで扱えるバイト列に変換すること、またはその変換規則を「エンコーディング」と呼びます。
エンコーディングには、UTF-8, UTF-16, UTF-32 などいくつかの方法があります。
UTF-16
そして、実は、上記のように単純に 16 bit 単位に変換する方法こそが UTF-16 というエンコーディング(の一部)なのです。
リトルエンディアンのものを UTF-16 LE、ビッグエンディアンのものを UTF-16 BE と呼んだりします。
しかし、現在の Unicode は、U+10FFFF(16 進数で 6 桁)までコードポイントを定義している(それだけたくさんの文字を集めて、文字集合が大きくなった)ので、この単純な方法だと破たんしてしまいます。
この対策としてサロゲートペアという方法が出てきます。16bit のバイナリを二つ組み合わせて U+FFFF より大きいコードポイントを表現する方法です。
これについては、ちゃんと詳しく説明してくれている書籍やサイトがたくさんあると思うのでここでは割愛します。
それから、受け取り手の立場になると、UTF-16 は UTF-16 でも、リトルエンディアンで送られてきたデータなのかビッグエンディアンで送られてきたデータなのかを識別したいですよね。
たとえば、先ほどの 'こんにちは' のデータを受け取った側が、事前にビッグエンディアンで送られてくるのかリトルエンディアンで送られてくるのかがわかっていなければ、3053 というデータが U+3053 のことなのか、それとも U+5330 のことなのかわかりませんね。
そのような時に、データの先頭にバイトオーダーマーク(Byte Order Mark: BOM)を入れることがあります。
BOM は U+FEFF というコードポイントが割り当てられています。(大文字だと E と F が識別しづらいですが、小文字で書くと、U+ f e f f です)
さきほどの 'こんにちは' の前に BOM をつけると、
ビッグエンディアンなら:
FEFF 3053 3093 306B 3061 306F
リトルエンディアンなら:
FFFE 5330 9330 6B30 6130 6F30
となります。
リトルエンディアンの時に出てくる FFFE というバイナリですが、U+FFFE というコードポイントは Unicode では未定義とされていますので、U+FFFE ではなく U+FEFF (BOM)がリトルエンディアンで送られてきているのだと判断できます。
というわけで、受け取った側は最初の 16bit を読んで FEFF ならビッグエンディアン、FFFE ならリトルエンディアンと判断できるわけです。
注意点としては、データに BOM をつけたら UTF-16 LE とか UTF-16 BE とは呼ばず、単に UTF-16 と呼ばなければならないということが挙げられます。
逆に、UTF-16 LE とか UTF-16 BE とか書いたら、データに BOM をつけてはいけないということになっています。
UTF-8
今度は "Hello" という文字列を UTF-16 で表現するとしたらどうなるでしょうか?
文字 コードポイント H U+0048 e U+0065 l U+006C l U+006C o U+006F
ビッグエンディアンだと
0048 0065 006C 006C 006F
ですし、リトルエンディアンだと
4800 6500 6C00 6C00 6F00
となるでしょう。
でもこれだとなんだか 00 が途中にたくさん入っているのでもったいないですね。
特に、普段アルファベットしか使わないアメリカなど英語圏の人々にとっては、この 0 はとても余計なものに見えることでしょう。
そこで、あるルールにのっとって、アルファベットは 1 バイトで、それ以外の文字(漢字など)は 2 バイト~ 6 バイトくらいのデータに変換してバイナリにする変換規則(エンコーディング)も考えられました。
たとえばひらがなの 'あ' (U+3042) は E3 81 82 という 3 バイトに変換されます。
漢字や仮名をたくさん使う日本人にとっては、一つの文字が 3 バイト以上になってしまうのは記憶容量の無駄のようにも思えますが、UTF-8 にはもちろんメリットもいくつかあります。
たとえば、変換後のバイト列の中に0が全く現れないので、従来のヌル終端文字列用の処理(文字列のコピーなど)がうまく動く場合が多いというメリットがあります。
それから、バイトオーダーの問題がなくなります。
変換ルールがちゃんと考えられているので、文字と文字の境目がわかりやすくなっています。
また、'/' などの記号のコードが途中に表れないようになっているので、ファイル名やディレクトリ名として安全に使えます。
これらのメリットから、通信や記録の際には UTF-8 が使われることが多いようです。
UTF-8 にはバイトオーダーの問題がないのですが、UTF-8 でエンコーディングされている、ということ自体を示すために、U+FEFF (BOM) を UTF-8 の規則で変換した EF BB BF という 3 バイトを先頭につけることがあります。
つまり、テキスト処理をするプログラムが先頭の 3 バイトを読んでみて EF BB BF だったら UTF-8 の可能性が高い、と判断できるわけです。
BOM 付きの場合単に UTF-8 と呼び、BOM なしの場合 UTF-8N と呼びます。
それから、UTF-8 の変換規則は、現在の Unicode よりも大きな文字集合である 'UCS4' の範囲のすべての文字を表すことができるというのも特徴です。
(UTF-16 はサロゲートペアを使っても U+10FFFF より大きなコードポイントを表現できないが、UTF-8 なら U+7FFFFFFF まで表現可能)
UTF-32
コードポイントを固定長で表現できるような簡単な方法もあるとうれしいですよね。各文字が固定長のバイナリに変換されると、文字列の長さをカウントしたりする処理がとても簡単になるなどのメリットがあります。
その場合には、UTF-32 というエンコーディングを使うとよいでしょう。
UTF-32 という変換規則にのっとると、先ほどの 'Hello' は
00000048 00000065 0000006C 0000006C 0000006F
というバイナリデータに変換されます。(各コードポイントを 32 bit で表現)
ちょっと贅沢な記憶領域の使い方に思えますが、記憶領域の経済性よりもデータとしての扱いやすさを重視する場合は有効な方法でしょう。
これにもリトルエンディアンとビッグエンディアンがあり、UTF-32 LE とか UTF-32 BE とか表記します。
BOM を入れたら LE や BE は付けず、単に UTF-32 と呼ぶのは UTF-16 と同様です。
UTF-32 の表現できる範囲は UTF-8 と同様、UCS4 という文字集合のすべてです。
その他のエンコーディング
実は、おなじみの Shift-JIS や EUC-JP も符号化方式の一種です。ただし、Shift-JIS や EUC-JP は Unicode よりも小さな文字集合にしか対応していない(Unicode 内のすべての文字をエンコーディングできるわけではない)と考えてください。(たとえば韓国語の文字やアラビア文字などが文字集合に含まれていない)
まとめ:
Unicode = 文字集合、UTF-8, UTF-16, UTF-32, ... はコードポイントを符号化する方式。
これだけ覚えておけば、Unicode が意外とすっきりしたものに思えてくるのではないでしょうか。
ていうか Joel on Software にはもっと面白おかしくわかりやすく書かれているのでぜひ読んでみてください。

当時のブログ記事に寄せられていた あまの 先輩のコメントも非常に参考になりますので合わせて掲載しておきます。
あと一点だけ、超初心者にも押さえておいて欲しい点があります。
それは正規化形式についてです。
「一文字に見える文字」(書記素クラスタといいます)が複数のコードポイントからなる場合があります。 そして同じ文字でも、複数通りの表現方法があり得ます。
たとえば「ば」は、U+3070 というコードポイント1つで表すこともできるし、U+306F U+3099 という2コードポイントで表現も可能です。
複数通りの表現方法のうち、どれを採用するかのルールが正規化形式です。
それがわからないと Win32 API の ::MultibyteToWideChar() の dwFlag で言うなら、MB_PRECOMPOSED と MB_COMPOSITE の使い分けが理解出来ないので。。。(前者が NFC、後者がNFDと呼ばれている正規化形式です)
つまり、「どの正規化形式を使い」、そして「どのエンコーディング方式でエンコードしているか」の両方を意識するようにして下さい。
以上です。